I also don't bother with SLA, never did. Imho that's for people who pay for service $40+ monthly and not us peasants, who pay $10 - $40 yearly.
Extension of a service date after longer outage is a nice gesture, but to specifically request and bother host for few pennies is just silly waste of time for both parties.
fully agree with @dgc1980 and @Mumbly
If you get 99% uptime for 50% of the price of 99,9% uptime its still a win.
but you have to understand what 99% uptime means and accept it.
@FrankZ@VirMach
After the machine migrated, I don't know about the situation of other nodes, the situation with lax1z014 is very bad.it has been experiencing frequent disconnections, ranging from 1 to 10 minutes each time, occurring several tens to hundreds of times per day. Essentially, the machine is no longer usable due to these disconnections. While we can understand that the performance and speed may be compromised as it is a discounted machine, the frequent disconnections are a quality issue. Are there any plans to fix this?
@sparkssss said: @FrankZ@VirMach
After the machine migrated, I don't know about the situation of other nodes, the situation with lax1z014 is very bad.it has been experiencing frequent disconnections, ranging from 1 to 10 minutes each time, occurring several tens to hundreds of times per day. Essentially, the machine is no longer usable due to these disconnections. While we can understand that the performance and speed may be compromised as it is a discounted machine, the frequent disconnections are a quality issue. Are there any plans to fix this?
Run MTR from your VPS to another location that we have like Amsterdam, Tokyo, NYC for a day and submit that in a ticket. Do it to one of our test IPs if possible so we can check it the other way around if there's any major issues and provide credentials in the ticket to your VPS for fastest resolution. Make sure to pick connection issue when making the ticket.
@sparkssss - It just so happens I have a VM with a DNS server on node LAX1Z014.
This is what my monitoring shows for the response time from my VM on LAX1Z014 for the day of October 26th.
Taking a longer view of October 19th to 26th, packet loss and ping times look like this.
So from the looks of the above graphs compared to the screenshot you posted here on October 10th we are having different experiences on node LAX1Z014. The conclusion that I come to from this is that it is not a node wide issue and is most likely an issue with your VM.
If you would DM me some information about the operating system, what you are running on your VM, the firewall setup, and if you want me to have a quick look around and see if I can ID your problem, some credentials for your VM.
I would like to once again make it clear that I do not work for Virmach, but am willing to attempt to work with you to resolve your problem.
EDIT: Since you mentioned that the problem started on or about October 1st, I can't help but think this may have something to do with the IP change that happened around that time. Could it be possable that your VM is not setup quite correctly regarding that change ?
@VirMach thanks for replay.
When my machine is inaccessible, I can still ping the IP and I scanned the open ports of the IP and found that port 3389 is open. However, my machine is running CentOS and I haven't opened port 3389. The possible reason could be that the IP has been assigned to multiple machines.There is another machine competing for the same IP address as mine.could u plz check?
When experiencing disconnections,
Starting Nmap 6.40 ( http://nmap.org ) at 2023-10-27 19:59 CST
Nmap scan report for 193.93.xx.xx
Host is up (0.18s latency).
Not shown: 999 filtered ports
PORT STATE SERVICE
3389/tcp open ms-wbt-server
while the normal status,it aligns with my situation.
Starting Nmap 6.40 ( http://nmap.org ) at 2023-10-27 20:05 CST
Nmap scan report for 193.93.xx.xx
Host is up (0.17s latency).
Not shown: 998 closed ports
PORT STATE SERVICE
80/tcp open http
443/tcp open https
@FrankZ said: @sparkssss - It just so happens I have a VM with a DNS server on node LAX1Z014.
This is what my monitoring shows for the response time from my VM on LAX1Z014 for the day of October 26th.
Taking a longer view of October 19th to 26th, packet loss and ping times look like this.
So from the looks of the above graphs compared to the screenshot you posted here on October 10th we are having different experiences on node LAX1Z014. The conclusion that I come to from this is that it is not a node wide issue and is most likely an issue with your VM.
If you would DM me some information about the operating system, what you are running on your VM, the firewall setup, and if you want me to have a quick look around and see if I can ID your problem, some credentials for your VM.
I would like to once again make it clear that I do not work for Virmach, but am willing to attempt to work with you to resolve your problem.
EDIT: Since you mentioned that the problem started on or about October 1st, I can't help but think this may have something to do with the IP change that happened around that time. Could it be possable that your VM is not setup quite correctly regarding that change ?
thanks for reply.
I just conducted a simple test and found that the possible reason is that the IP address may be assigned to multiple machines, causing frequent disconnections.I hope that these disconnections are not a widespread issue.
@sparkssss said: thanks for reply.
I just conducted a simple test and found that the possible reason is that the IP address may be assigned to multiple machines, causing frequent disconnections.I hope that these disconnections are not a widespread issue.
Probably not wide spread, since this is the complaint thread. If you feel that you have ID'd the issue then may I suggest posting your VM ID so VirMach can identify the IP in question.
@VirMach - Just a FYI, LAX1Z012 seem to be having issues. Gateway IP is up, but my VM shutdown and will not restart. Pinging a dozen IPs around mine, receives no response.
@sparkssss said: @VirMach thanks for replay.
When my machine is inaccessible, I can still ping the IP and I scanned the open ports of the IP and found that port 3389 is open. However, my machine is running CentOS and I haven't opened port 3389. The possible reason could be that the IP has been assigned to multiple machines.There is another machine competing for the same IP address as mine.could u plz check?
When experiencing disconnections,
Starting Nmap 6.40 ( http://nmap.org ) at 2023-10-27 19:59 CST
Nmap scan report for 193.93.xx.xx
Host is up (0.18s latency).
Not shown: 999 filtered ports
PORT STATE SERVICE
3389/tcp open ms-wbt-server
while the normal status,it aligns with my situation.
Starting Nmap 6.40 ( http://nmap.org ) at 2023-10-27 20:05 CST
Nmap scan report for 193.93.xx.xx
Host is up (0.17s latency).
Not shown: 998 closed ports
PORT STATE SERVICE
80/tcp open http
443/tcp open https
You are using the old dedipath IP.
Dedipath was down for one month.
Submit ticket for a new IP.
@FrankZ said: Probably not wide spread, since this is the complaint thread. If you feel that you have ID'd the issue then may I suggest posting your VM ID so VirMach can identify the IP in question.
Seems like sometimes it's easier to just look at arp/mac addresses than try to communicate back and forth. You're definitely a better front-facing support agent than I am.
Anyway, it should be fixed. Maybe. At least one of the two or more people have to play musical chairs though within their VM depending on whether they decided to go with what was assigned to them or whatever they felt like doing, it was a SolusVM feature also known as ebtables randomly breaking. It could also be the other SolusVM feature where the database shows one IP and assigns another but that one's more rare recently and I didn't see any signs of that, at least not in the amount of time I could allocate.
@sparkssss said: thanks for reply.
I just conducted a simple test and found that the possible reason is that the IP address may be assigned to multiple machines, causing frequent disconnections.I hope that these disconnections are not a widespread issue.
Probably not wide spread, since this is the complaint thread. If you feel that you have ID'd the issue then may I suggest posting your VM ID so VirMach can identify the IP in question.
so,where i can find my vm id?
as nightcat said,how to describe my situation in the ticket?
@FrankZ said: @VirMach - Just a FYI, LAX1Z012 seem to be having issues. Gateway IP is up, but my VM shutdown and will not restart. Pinging a dozen IPs around mine, receives no response.
DALZ007: Node has been down since the dedipath problem I think
Operation Timed Out After 90000 Milliseconds With 0 Bytes Received
Affecting System - DALZ004, DALZ007
Update 10/20/23 -- we believe the servers have finally arrived from Dallas to Atlanta today. Since it's the weekend, we'll likely have them racked early next week.
too bad that the least server I care about out of them, there is nothing there. but yeah, I missed reading that part from the status page, thanks to my sucks english


Comments
^ This +1.
I also don't bother with SLA, never did. Imho that's for people who pay for service $40+ monthly and not us peasants, who pay $10 - $40 yearly.
Extension of a service date after longer outage is a nice gesture, but to specifically request and bother host for few pennies is just silly waste of time for both parties.
SLA is just marketing gimmick. and so is 24/7/365 support
I bench YABS 24/7/365 unless it's a leap year.
fully agree with @dgc1980 and @Mumbly
If you get 99% uptime for 50% of the price of 99,9% uptime its still a win.
but you have to understand what 99% uptime means and accept it.
@FrankZ @VirMach
After the machine migrated, I don't know about the situation of other nodes, the situation with lax1z014 is very bad.it has been experiencing frequent disconnections, ranging from 1 to 10 minutes each time, occurring several tens to hundreds of times per day. Essentially, the machine is no longer usable due to these disconnections. While we can understand that the performance and speed may be compromised as it is a discounted machine, the frequent disconnections are a quality issue. Are there any plans to fix this?
Yea, @FrankZ, fix it! Now!
Run MTR from your VPS to another location that we have like Amsterdam, Tokyo, NYC for a day and submit that in a ticket. Do it to one of our test IPs if possible so we can check it the other way around if there's any major issues and provide credentials in the ticket to your VPS for fastest resolution. Make sure to pick connection issue when making the ticket.
Once that's provided, I'll have FrankZ fix it.
That sounds like effort, a lot of effort.
Can't FrankZ intern handle it himself if user provide login/pass!?
Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png
@sparkssss - It just so happens I have a VM with a DNS server on node LAX1Z014.
This is what my monitoring shows for the response time from my VM on LAX1Z014 for the day of October 26th.
Taking a longer view of October 19th to 26th, packet loss and ping times look like this.
">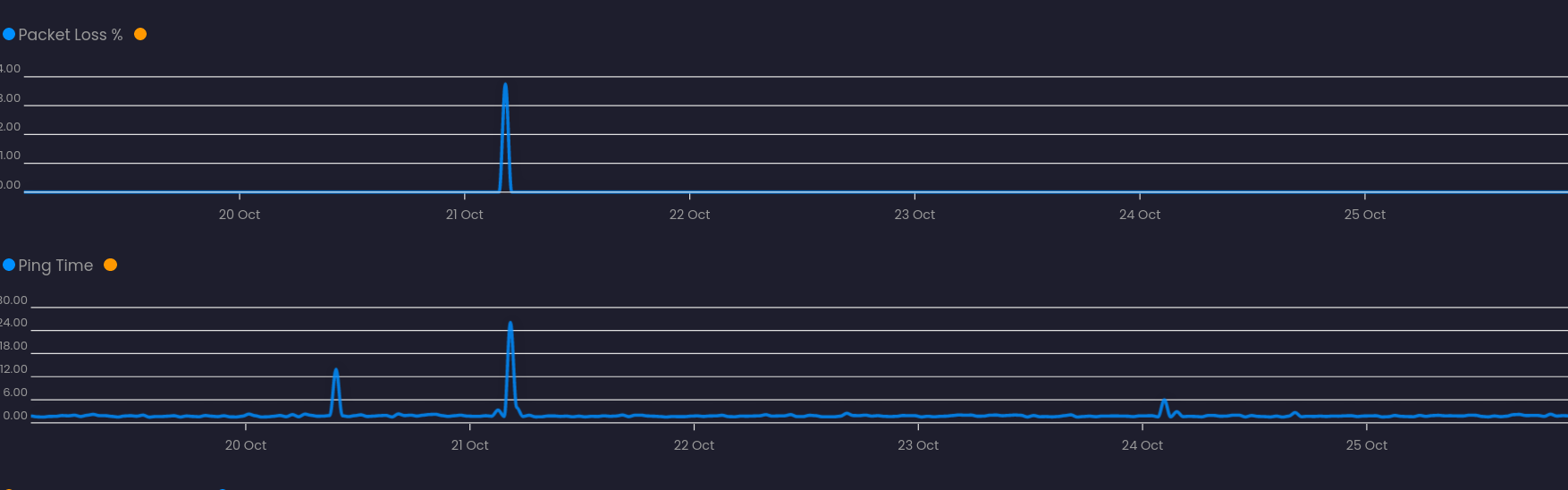
So from the looks of the above graphs compared to the screenshot you posted here on October 10th we are having different experiences on node LAX1Z014. The conclusion that I come to from this is that it is not a node wide issue and is most likely an issue with your VM.
If you would DM me some information about the operating system, what you are running on your VM, the firewall setup, and if you want me to have a quick look around and see if I can ID your problem, some credentials for your VM.
I would like to once again make it clear that I do not work for Virmach, but am willing to attempt to work with you to resolve your problem.
EDIT: Since you mentioned that the problem started on or about October 1st, I can't help but think this may have something to do with the IP change that happened around that time. Could it be possable that your VM is not setup quite correctly regarding that change ?
@VirMach thanks for replay.
When my machine is inaccessible, I can still ping the IP and I scanned the open ports of the IP and found that port 3389 is open. However, my machine is running CentOS and I haven't opened port 3389. The possible reason could be that the IP has been assigned to multiple machines.There is another machine competing for the same IP address as mine.could u plz check?
When experiencing disconnections,
Starting Nmap 6.40 ( http://nmap.org ) at 2023-10-27 19:59 CST
Nmap scan report for 193.93.xx.xx
Host is up (0.18s latency).
Not shown: 999 filtered ports
PORT STATE SERVICE
3389/tcp open ms-wbt-server
while the normal status,it aligns with my situation.
Starting Nmap 6.40 ( http://nmap.org ) at 2023-10-27 20:05 CST
Nmap scan report for 193.93.xx.xx
Host is up (0.17s latency).
Not shown: 998 closed ports
PORT STATE SERVICE
80/tcp open http
443/tcp open https
thanks for reply.
I just conducted a simple test and found that the possible reason is that the IP address may be assigned to multiple machines, causing frequent disconnections.I hope that these disconnections are not a widespread issue.
Probably not wide spread, since this is the complaint thread. If you feel that you have ID'd the issue then may I suggest posting your VM ID so VirMach can identify the IP in question.
@VirMach - Just a FYI, LAX1Z012 seem to be having issues. Gateway IP is up, but my VM shutdown and will not restart. Pinging a dozen IPs around mine, receives no response.
You are using the old dedipath IP.
Dedipath was down for one month.
Submit ticket for a new IP.
Seems like sometimes it's easier to just look at arp/mac addresses than try to communicate back and forth. You're definitely a better front-facing support agent than I am.
Anyway, it should be fixed. Maybe. At least one of the two or more people have to play musical chairs though within their VM depending on whether they decided to go with what was assigned to them or whatever they felt like doing, it was a SolusVM feature also known as ebtables randomly breaking. It could also be the other SolusVM feature where the database shows one IP and assigns another but that one's more rare recently and I didn't see any signs of that, at least not in the amount of time I could allocate.
so,where i can find my vm id?
as nightcat said,how to describe my situation in the ticket?
Virmach said above that your VM is already fixed.
(but of course everybody knows that I really fixed it)
For future reference, you can find your VM ID by signing in to the billing panel, clicking through to the product details of the VM in question, and then looking at the URL
IE: https://billing.virmach.com/clientarea.php?action=productdetails&;id=690069
In the example "690069" would be the VM ID.
Wasn't fixed, now it is. Was also the second issue as well. Have I mentioned how much I love SolusVM?
VirMach SolusVM
SolusVM
Oh god
@VirMach @FrankZ
I see that the IP has been changed. I will continue to monitor the situation and provide feedback if any issues arise. Thanks.
VirMach fixed IPs manually.
LAX1Z012 is broken.
Coincidence?
Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png
OK where I am I? Not cool man not cool!!!
edit: Best SLA ever "It will be up 100% of the time it is up."
The Yeti has left the building.
My servers situation, is anyone on the same nodes and the server is live?
LAX1Z016 (2 servers) & NYCB028 (1 server)
Main IP pings: false
Node Online: true
Service online: online
Tried the Reconfigure button, result: Operation Timed Out After 90000 Milliseconds With 0 Bytes Received
DALZ007: Node has been down since the dedipath problem I think
Operation Timed Out After 90000 Milliseconds With 0 Bytes Received
PS: I'm a super noob in Linux and my English sucks.
Affecting System - DALZ004, DALZ007
Update 10/20/23 -- we believe the servers have finally arrived from Dallas to Atlanta today. Since it's the weekend, we'll likely have them racked early next week.
too bad that the least server I care about out of them, there is nothing there. but yeah, I missed reading that part from the status page, thanks to my sucks english
I have 2 VMs on LAXA016, one of them fails to start and fails to connect via VNC.
Such captive doggy, no barking!
such tame strawberry, no whining!
I bench YABS 24/7/365 unless it's a leap year.
Such fragile snowflake, no crying!