@tulipyun said:
The feature for migrating instances appears to have been removed.
Its been sunset
Never to return
Long like VirBot migration
You will be remembered well
Turned off to avoid potential issues as I reworked parts of the shared system for migrations. It's working better now for mass migrations, but I have to spend some time to re-test individual migration feature before turning it back on.
started moving TYOC038 to a new node, TYOC032.
That one ran into problems. I feel like that's a good example to point to on why it's not done.
Any EYA on this? Checking too many times, I was logged out for a full day.
Last November, I was double-charged by PayPal for a payment I made.
My support ticket has been pending for quite some time now; could you please assist me with this? A refund is not necessary; simply converting the duplicate payment amount into account credit would suffice.
strange that this did not happen automatically.
usually when you set up a paypal subscription and paypal automatically sends the money and you also manually pay it goes against the same original invoice number and the system updates your credit balance, have you checked your credit balance?
You have no notifications at this time.
already check ,none credit balance
That's tough... Hopefully they sort it out for you @VirMach
@FrankZ said:
Hey @VirMach how's it going. Hope life is treating you well.
I've definitely made some time for other things, most of it happening/starting around the time everyone thought I disappeared. I tried cutting back hours to what would be considered "normal" after the first San Jose incident occurred. Obviously, it did it not work out very well so I've been back to working closer to what I normally did (for a while now.)
I finally started "seriously" gardening to properly mark being in my 30's and going back to living on a property with a backyard. I basically try to go outside for about 20 minutes every day and mostly quite literally touch grass since there's not much left to do.
With how "well" it's going in Oklahoma weather, I don't think I have to worry about this, but I haven't quite yet figured out what to do with all the strawberries that come in next year. I think it's going to be something like 150 pounds of strawberries. I'm sure the bugs, birds and squirrels will figure out what to do with them.
@tenpera said: started moving TYOC038 to a new node, TYOC032.
That one ran into problems. I feel like that's a good example to point to on why it's not done.
Any EYA on this? Checking too many times, I was logged out for a full day.
This is something that's currently being worked on, alongside IP renumbering planning, and San Jose. Some progress has been made but it likely will not be until at least the next few days for a solution to be found.
Alpha/beta monitoring system caused an overload. I haven't figured out why. Let me know if you notice anything else or if you were able to power your service back on.
I knew Virmach offered poor service years ago, yet its actual performance turns out to be far worse than expected. The SJC node has been offline for nearly half a year with no proper solutions provided, which is quite unbelievable. I wonder how users with high-priced plans are getting on.
@aiexo said:
I knew Virmach offered poor service years ago, yet its actual performance turns out to be far worse than expected. The SJC node has been offline for nearly half a year with no proper solutions provided, which is quite unbelievable. I wonder how users with high-priced plans are getting on.
Can't say I did not warn you.
@aiexo said: Mod EDIT by FrankZ: I am going to ask you to stop doing this. The only thing that you have contributed to this community is 20+ comments on the same issue of you buying a scalped account and wanting VirMach to fix it up for you. Please deal with this through VirMach's ticket system. Next comment on this subject will get you banned here as well, but feel free to make comments on any other subject.
@aiexo said:
I knew Virmach offered poor service years ago, yet its actual performance turns out to be far worse than expected. The SJC node has been offline for nearly half a year with no proper solutions provided, which is quite unbelievable. I wonder how users with high-priced plans are getting on.
Can't say I did not warn you.
@aiexo said: Mod EDIT by FrankZ: I am going to ask you to stop doing this. The only thing that you have contributed to this community is 20+ comments on the same issue of you buying a scalped account and wanting VirMach to fix it up for you. Please deal with this through VirMach's ticket system. Next comment on this subject will get you banned here as well, but feel free to make comments on any other subject.
Indeed. I once bought resold premium instances, and felt humiliated during communications. I have completely abandoned all Virmach servers long ago.
I once recommended this provider to many friends. They barely use the services and always turn to me for help when issues occur. I logged into the dashboard today and surprisingly found the servers have been shut down for half a year. I feel guilty towards my friends, so I decide to speak out again. Feel free to make fun of me as before.
I wonder why you are so partial to this brand. Are you getting any benefits from it? No one will defend others groundlessly without personal interests or kinship ties.
@aiexo said:
I wonder how users with high-priced plans are getting on.
What? They actually have customers who’ve bought the high-priced plans?
Who knows.
I’ve provided my friend with a GreenCloud server on the SoftBank line, and he is very pleased with its network speed. He simply wants to check if those 2019 Virmach instances are fully out of service.
@aiexo said: I wonder why you are so partial to this brand. Are you getting any benefits from it? No one will defend others groundlessly without personal interests or kinship ties.
I know it's been a while since you have been around LES, but everybody thinks I AM @VirMach.
So that probably explains it.
Rumor says this whole thread, including @VirMach@FrankZ and all other users, are LLM generated.
The LES code has a special bypass that routes requests to this thread to the VirBot LLM.
Each user is interacting with their own edition of this thread.
We've seen the artifacts in the flan.
@yoursunny said:
Rumor says this whole thread, including @VirMach@FrankZ and all other users, are LLM generated.
The LES code has a special bypass that routes requests to this thread to the VirBot LLM.
Each user is interacting with their own edition of this thread.
We've seen the artifacts in the flan.
..... but there is probably even more to the story.
I feel like either all Virmach clients are now either fully used to their server being ephemeral or left already. So no one around to start drama... What happened to the guy who used to post AI generated clown to complain?
I’ve been digging into the persistent issue regarding the incorrect GeoIP localization for VirMach’s Netherlands-based infrastructure (operated under Virtual Machine Solutions LLC) and why manual correction submissions to MaxMind have been consistently reverted or ineffective.
Here is the root cause of the issue:
The Downstream Geofeed Dependency
Modern GeoIP database providers (such as MaxMind, Google, Cloudflare, etc.) heavily rely on automated ingestion pipelines that periodically pull RFC 8805-compliant Geofeed files maintained by network operators.
Downstream providers operating under xTom (ASN 3214)—including VirMach (Virtual Machine Solutions LLC), Hizakura B.V., and GreenCloud—frequently lease or route their IP space directly from xTom. Consequently, major GeoIP platforms default to reading the upstream Geofeed published by xTom rather than individual downstream correction requests.
The Flaw in the Upstream Database
The breakdown occurs because xTom’s official, centralized Geofeed repository contains incorrect metadata for these specific subnets. You can verify this by checking their publicly exposed CSV file:
In this file, the subnets deployed in Amsterdam are mislabeled with incorrect country/city attributes. Every time MaxMind or Google recrawls this upstream file, any manual overrides or corrections previously submitted by users or downstream VPS providers are automatically overwritten and reverted back to the incorrect location.
Moving Forward
Submitting individual tickets to MaxMind is a temporary band-aid that will inevitably get overridden during the next sync cycle.
The definitive solution requires xTom’s Network Operations Center (NOC) to correct the metadata rows inside as-xtom.csv.
I am currently reaching out to their NOC ([email protected]) to report this routing and geolocation mismatch. (Although I don't think they'll reply or make any changes LOL.)
If you are a downstream provider affected by this, I highly recommend opening a ticket with xTom as well to accelerate the update.


Comments
What is the current service transfer policy between accounts?
Long live VirBot @VirMach
started moving TYOC038 to a new node, TYOC032.
That one ran into problems. I feel like that's a good example to point to on why it's not done.
Any EYA on this? Checking too many times, I was logged out for a full day.
It's been processed.
Credit balance added.
Hey @VirMach how's it going. Hope life is treating you well.
I shall also pllead my double payment ticket also from November, Ticket#938125 @VirMach
As with Herman, I'd be very grateful for the account credit.
RIP AMSD018
kernel:[3689506.627677] watchdog: BUG: soft lockup - CPU#0 stuck for 21s! [jbd2/vda1-8:157]Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png
I am so happy with my vps servers at @VirMach")
Virmach Deals
I've definitely made some time for other things, most of it happening/starting around the time everyone thought I disappeared. I tried cutting back hours to what would be considered "normal" after the first San Jose incident occurred. Obviously, it did it not work out very well so I've been back to working closer to what I normally did (for a while now.)
I finally started "seriously" gardening to properly mark being in my 30's and going back to living on a property with a backyard. I basically try to go outside for about 20 minutes every day and mostly quite literally touch grass since there's not much left to do.
With how "well" it's going in Oklahoma weather, I don't think I have to worry about this, but I haven't quite yet figured out what to do with all the strawberries that come in next year. I think it's going to be something like 150 pounds of strawberries. I'm sure the bugs, birds and squirrels will figure out what to do with them.
This is something that's currently being worked on, alongside IP renumbering planning, and San Jose. Some progress has been made but it likely will not be until at least the next few days for a solution to be found.
Alpha/beta monitoring system caused an overload. I haven't figured out why. Let me know if you notice anything else or if you were able to power your service back on.
Oh right Oklahoma. One of my 4TB NVMe drives died yesterday.
https://www.speedtest.net/result/19224284106
Not bad on NY location.
Get some hosting at https://drserver.net .
This is unfortunate
I knew Virmach offered poor service years ago, yet its actual performance turns out to be far worse than expected. The SJC node has been offline for nearly half a year with no proper solutions provided, which is quite unbelievable. I wonder how users with high-priced plans are getting on.
Can't say I did not warn you.
What? They actually have customers who’ve bought the high-priced plans?
Indeed. I once bought resold premium instances, and felt humiliated during communications. I have completely abandoned all Virmach servers long ago.
I once recommended this provider to many friends. They barely use the services and always turn to me for help when issues occur. I logged into the dashboard today and surprisingly found the servers have been shut down for half a year. I feel guilty towards my friends, so I decide to speak out again. Feel free to make fun of me as before.
I wonder why you are so partial to this brand. Are you getting any benefits from it? No one will defend others groundlessly without personal interests or kinship ties.
Who knows.
I’ve provided my friend with a GreenCloud server on the SoftBank line, and he is very pleased with its network speed. He simply wants to check if those 2019 Virmach instances are fully out of service.")
Friends ? Right, got it.
I know it's been a while since you have been around LES, but everybody thinks I AM @VirMach.
So that probably explains it.
EDIT: Oops, must have hit that ban button.
What a dramatic scene.
Did I miss something? Why did that guy suddenly got banned?
We have history.
Ooo, elaborate! I got my popcorn ready
Thread getting a little slow ....
Rumor says this whole thread, including @VirMach @FrankZ and all other users, are LLM generated.
The LES code has a special bypass that routes requests to this thread to the VirBot LLM.
Each user is interacting with their own edition of this thread.
We've seen the artifacts in the flan.
Daniel fan club 😎 affbrr
..... but there is probably even more to the story.
As usual, I finished my popcorn before the show/movie begun...
I feel like either all Virmach clients are now either fully used to their server being ephemeral or left already. So no one around to start drama... What happened to the guy who used to post AI generated clown to complain?
Hi @FrankZ
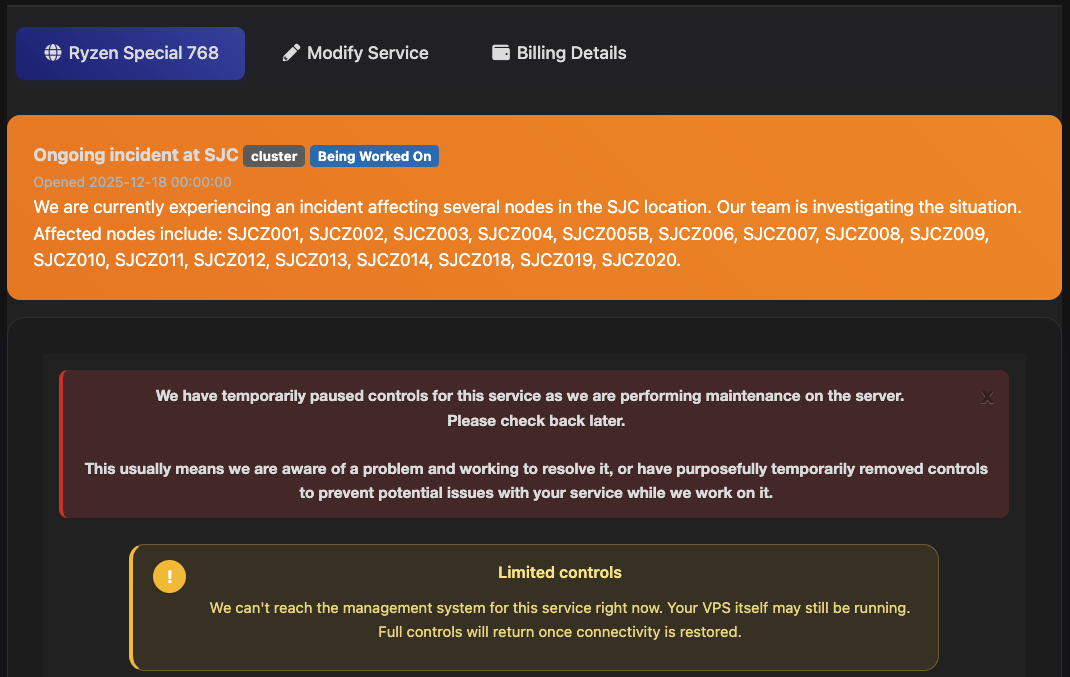
When do you think my San Jose small plate chicken will be resurrected?
The Ultimate Speedtest Script | Get Instant Alerts on new LES/LET deals | Cheap VPS Deals | VirMach Flash Sales Notifier
FREE KVM VPS - FreeVPS.org | FREE LXC VPS - MicroLXC
On the OGF harassing other providers. I expect he might run a service for hire.
Hi !! good to see you.
Let's see if some magic fingers will help ......
I’ve been digging into the persistent issue regarding the incorrect GeoIP localization for VirMach’s Netherlands-based infrastructure (operated under Virtual Machine Solutions LLC) and why manual correction submissions to MaxMind have been consistently reverted or ineffective.
Here is the root cause of the issue:
Modern GeoIP database providers (such as MaxMind, Google, Cloudflare, etc.) heavily rely on automated ingestion pipelines that periodically pull RFC 8805-compliant Geofeed files maintained by network operators.
Downstream providers operating under xTom (ASN 3214)—including VirMach (Virtual Machine Solutions LLC), Hizakura B.V., and GreenCloud—frequently lease or route their IP space directly from xTom. Consequently, major GeoIP platforms default to reading the upstream Geofeed published by xTom rather than individual downstream correction requests.
The breakdown occurs because xTom’s official, centralized Geofeed repository contains incorrect metadata for these specific subnets. You can verify this by checking their publicly exposed CSV file:
Upstream Geofeed URL: https://geofeed.xtom.de/files/as-xtom.csv
In this file, the subnets deployed in Amsterdam are mislabeled with incorrect country/city attributes. Every time MaxMind or Google recrawls this upstream file, any manual overrides or corrections previously submitted by users or downstream VPS providers are automatically overwritten and reverted back to the incorrect location.
Submitting individual tickets to MaxMind is a temporary band-aid that will inevitably get overridden during the next sync cycle.
The definitive solution requires xTom’s Network Operations Center (NOC) to correct the metadata rows inside as-xtom.csv.
I am currently reaching out to their NOC ([email protected]) to report this routing and geolocation mismatch. (Although I don't think they'll reply or make any changes LOL.)
If you are a downstream provider affected by this, I highly recommend opening a ticket with xTom as well to accelerate the update.