

Local AI / LLM - and my step-by-step setup
 bikegremlin
ModeratorOGContent Writer
bikegremlin
ModeratorOGContent Writer
I made a local LLM work on my Windows PC, using (for now still) free software, and no Docker.
As simple and idiot-friendly as it gets.
DeepSeek wrote a well-functioning WordPress website scraper, so I could feed all my public knowledge (from my websites) - along with my private Deathnotes.
Here is an example:
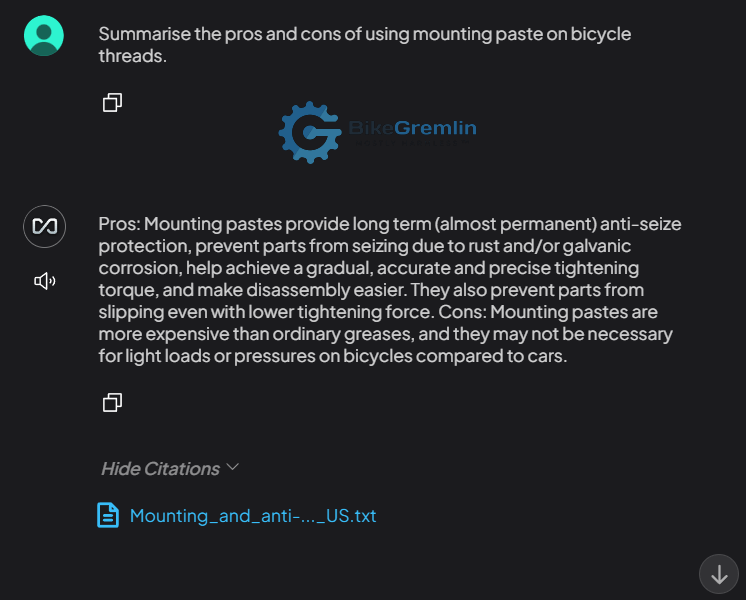
Why is this impressive? Because I’m a huge fan of anti-seize mounting pastes and use them on practically every bolt! 🙂 However, my notes and articles are fucking objective (LOL). So, what the “robot” answered is in fact correct, even if I don’t like or follow that answer (I always err to the side of caution and use anti-seize). This is actually very good, and perhaps even more correct than I would answer, because I would have recommended anti-seize a bit more “aggressively” so to speak.
The full notes about my local AI setup:
https://io.bikegremlin.com/37912/self-hosted-no-docker-ai-lm-studio-anythingllm-setup/
Comments
Thought the dashboard looked familiar…
Anythingllm is good baseline
Best regards
blog archives
The model - do you think it's a good choice for this use case?
Nous Hermes 2 – Mistral 13B model in GGUF format, quantized to Q5_K_M.
🔧 BikeGremlin guides & resources
Hmm, I need a AI that can read the steps and set it up for me... And another AI to test it, and anoter AI use it... Can I get a AI that will do everything for me like the "WALL-E" movie...
You'll probably get that pretty soon - and it won't be voluntary. LOL.")
Jokes aside, this is pretty simple (long text perhaps, but the procedure is step-by-step).
🔧 BikeGremlin guides & resources
Anybody got any good results on ways to integrate search?
Finding myself leaning more & more on online AIs because LLM+Search is better for most of my tech research than either search or LLM separately.
So far Brave API and SearXNG seem like best candidates but haven't actually found time to try it yet. SearXNG I'm pretty sure I'd need to stick on a VPS...cause I heard it fucks up the IP you're on. Not in usual IP rep sense as LES understands it. Google sees the automated search traffic and thus gives you grief on your own casual browsing, logs you out of gmail etc.
@bikegremlin
I use anythingllm almost exclusively for API (grok/cohere/generic API based, etc) so I cannot say my experience with Nous Hermes 2 – Mistral 13B specifically. Local install I had done with lmstudio, on an older machine (i5/6500T old..) and other than fans spinning continuously for larger models (Phi4 and lighter gemini ran well) mistral small also worked well...
Click to view Screenshots- Anythingllm on Debian/LInux Mint
@havoc take a look at turboseek : https://www.turboseek.io/ ;
this guy's other projects are interesting too! https://github.com/Nutlope/turboseek
Side note: I have turned that modded desktop off- since the electricity bills exceeded "free" units for two months in a row, and we had to pay the bill. I need to bring below it to get "free" electricity again....so maybe I will try local install next month..
blog archives
Hmm.
I don't use that a lot, and my PC is quite energy-efficient for its power (that was how I picked components).
Will see when the time comes, but I don't expect huge electricity bills (my UPS keeps a track of my PC's power usage).
🔧 BikeGremlin guides & resources
Take a look at Huggingface API also. Some interesting models, you can set up and run in terminal.
hm.. the desktop takes only about 5-6 percent of the monthly consumption but enough to tip the balance.
blog archives
Ya, installing it on windows is pretty easy, but getting the UI up is more troublesome. For me, i prefer to deploy it using docker since both are packed together.
Anybody having luck on linux? Neither the appimage nor docker launch for me
Did you try:
https://github.com/maxmcoding/deepseek-docker/blob/main/docker-compose-cpu-based.yml
Better guide: https://diycraic.com/2025/01/29/how-to-host-deepseek-locally-on-a-docker-home-server/
Once the UI is up, you can pull the latest image by downloading the model by tag: https://ollama.com/library/deepseek-r1/tags
Meant the AnythingLLM part. Tried both the docker run off their site and messed around with docker compose. May have something to do with me using podman instead of docker though.
Serving models part I've got covered pretty well.
See the screenshots I posted above. ☝️ Anythingllm on Linux mint.
Try the installer not applimage
blog archives
Tried that ahead of docker.
On that the fault is likely with my system though. Arch/Hyprland/Wayland...so doesn't seem to play nice with GTK.
I'll figure it out eventually. Or just stick it on a VM/LXC
Ache Linux.")
Playing it on hard.")
🔧 BikeGremlin guides & resources
Bad decisions i made yesterday:
1. Decided to try running ollama with deepseek 8M on CPU only, on my home server.
2. Decided to give it all the beans... all 72 threads to ollama. Reached ~7200% CPU usage on "top" while generating an answer.
3. Decided to keep generating answers back to back for about 30 mins, without monitoring temps.
So ya, server overheated and halted... Max power consumption was about 400W (according to my power meter). My CPU coolers are rated 150Ws each, so they were VERY hot to the touch... Took nearly 20 mins before I could power it back on. Not sure how much of the VRM lifetime was used up... Probably need to replace the thermal paste as well. Lucky i was planning to replace the mobo soon (already ordered last week).
Lessons learnt... nil
Next i'll try the same on my gaming desktop running AMD cpu + gpu...
https://github.com/assafelovic/gpt-researcher
what kind of "linux" are you using here?
I have 2x4 3090 production setup using ubuntu 24 lts, the stack being used is sglang, vllm, with help from lmdeploy.
overall setup is
Fuck this 24/7 internet spew of trivia and celebrity bullshit.
@Encoders
Arch. I've got cuda in containers working. Current issue is something more pedestrian. Somehow it's not happy with the DB it's trying to create.
Thinking I'll just do inference and anythingllm on separate machines. Guess I'd lose GPU acceleration on the embeddings part but that shouldn't have too much on an impact.
The qwen A3B style MoE models should totally work on CPU only. Even on my decidedly ancient home server setup I'm getting usable speeds
Single Core | 1256
Multi Core | 7121
Deepseek also runs, the issue was me thinking "more power!"
Can I replicate this on my VPS without GPU?
I fear the Emperor forbids such malpractice... beside the fact that Silica Animus itself is an abomination!
Jokes aside:
LLMs can work on CPU alone, but you should use a "lighter" model - and performance will still be pretty bad.
Best The least bad practical approach:
If the sexual giant @Amadex is telling truth, DeepSeek API (to name one) is dirt-cheap!
🔧 BikeGremlin guides & resources
Thank you. I still want to run it local. I am in the right place to find a decent VPS. So, a VPS with dedicated 4 cores will do?
Sigh. We are too poor... or the tech. is too young still - whichever way of putting it makes you feel better.")
On a 4-core VPS, especially the real VPS (not the "semi-dedicated" VPS), you will get crappy performance, even with low-end LLMs.
I asked ChatGPT for options that just might work.
I can't think of any, and can't confirm fi I got a bullshit answer, but here is what the robot replied:
✅ Best lightweight models for CPU (sorted by usability)
Model Name Size (GGUF Q4/Q5) Notes
Phi-2 ~1.8–2.5 GB MS open model, good reasoning for its size. Great on CPU.
TinyLlama-1.1B ~0.5–1.2 GB Tiny, shockingly usable for Q&A and basic tasks.
Gemma-2B ~2.5–3.5 GB Google's small model. Good balance.
MythoMax-L2 7B ~4–6 GB One of the best “smart” 7B chat models. Slower on CPU but doable.
Mistral-7B-Instruct ~4.5–6.5 GB Solid general-purpose model. Use Q4_K_M or Q5_K_M for balance.
🧠 Practical advice
Stick to 1B–2B models for comfortably usable speed on CPU
Use Q4_0 or Q5_K_M quantisation
Tools: llama.cpp, LM Studio, or text-generation-webui with CPU backend
Batch processing, not live chat, is your friend on weak CPUs
🛠 Example VPS setup (that actually works well):
4 vCPU
16 GB RAM
Swap file enabled
Model: Phi-2 Q5_K_M or TinyLlama Q5_0
Response times: ~2–5 seconds per reply (manageable)
🔥 TL;DR:
Want it fast on CPU?
🏆 Phi-2
🏆 TinyLlama
These are shockingly good for their size and run decently even on potato-tier VPS boxes.
Want me to give you direct GGUF download links?
BIKEGREMLIN: That last line, that's also the robot, offering more info if prompted.
🔧 BikeGremlin guides & resources
Thank you for thoughtful and well researched answer. I am now convinced that I have to find one of the OVH dedicated server deals
On openrouter you can sort by price and set limit to zero. There is usually a surprisingly large range of free ones that is API enabled.
For paid it's worth taking a closer look at their caching strategy too. e.g. DeepS caches till bytes that no longer matches so if you know you'll feed same info again & again that needs to be at start of prompt and the parts that change at the end.
The cheapest and hassle free way to run a good AI chat is:
Amadex • Hosting Forums • root.hr
Or, Use leo ai on brave browser with api keys from your preferred provider..
list of duck.ai and some other browser based llm tools if horsepower constrained
blog archives