

[Free] Server Management with AI - Alpha release - seeking feedback
 evnix
OG
evnix
OG
Hey LES 👋
I wanted to share something I've been quietly working on and would love your thoughts.
it's LoadMyCode: an experimental platform that lets you chat with your Linux servers using natural language.
What it does (kind of/sort of):
- Chat interface for server management
- AI translates your requests into actual instructions
- Real-time feedback from your servers
- Each server gets its own "personality" (still figuring this part out!)
- We're also experimenting with multi-server conversations, imagine chatting with several servers at once, or having team members collaborate in the same chat where servers can "talk" to each other and coordinate tasks
The wild part we're exploring:
The idea that servers, team members, and AI enables servers could all be in the same conversation figuring things out together. Like "Hey webserver and DB server, can you guys form a private network" while your teammate jumps in with context. It sounds crazy when I type it out, but I think there might be something there.
Why I'm posting here:
It is in very early alpha and honestly, I am not sure if this is useful or just a fun experiment.
If anyone's curious enough to try it out or just wants to chat about the concept, I'd genuinely appreciate any feedback: positive, negative, or just "this is weird but interesting."
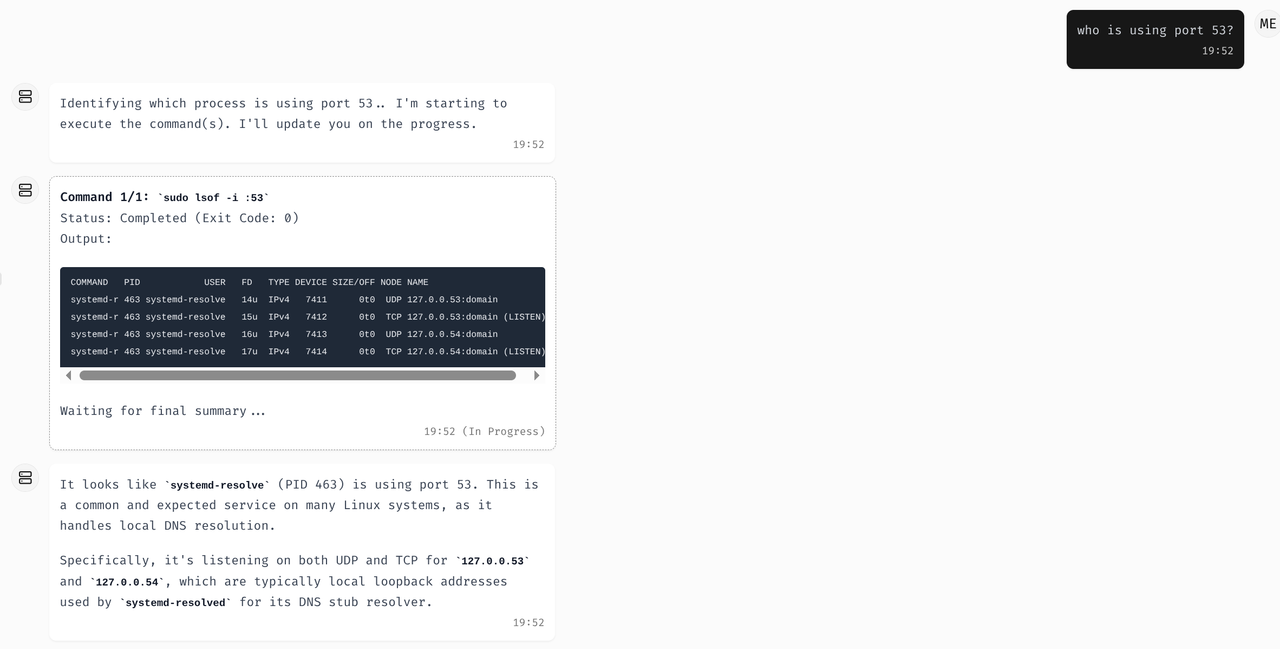
P.S. - It uses GitHub login and I am being very careful, but again, please don't use this for anything critical. Its an early alpha only tested on fresh Ubuntu instances, and if anything feels broken, just refresh the page. There aren't really usage limits right now, but I'm bootstrapping this myself and good-quality AI inference costs add up quickly, so I'd really appreciate being thoughtful with usage if you decide to try it out, just don't go crazy with it! 😅 have fun!
My Personal Blog | Currently Building LoadMyCode
Comments
Cool idea.
Yo Serverman, what does rm -rf /* do?
“Hold on homie, let me check. brb”
Alert: Serverman is unreachable.
Why?
Lol, yeah we did think about this.
There are a few safeguards against this but yeah I won't promise if any of it is fool proof at this stage.
I am working on tricky cases like
rm -rf /home/user/$VAR when $VAR itself might be empty. but yeah just be careful.
My Personal Blog | Currently Building LoadMyCode
I already broken the safeguard
nice!!
Note: There are no safegaurds if you specifically push it to do certain dangerous things despite the warnings")
My Personal Blog | Currently Building LoadMyCode
Interesting. I did test it and it was impressive. Still a long way to go. Keep it up!
Just curious what's the market for this?
The Yeti has left the building.
Interesting! If i am correct, would it be more of a AI (using some existing AI in the backend, like deepseek or Llama or something else open source) and guar railing it to server management stuff?
In future, do you actually plan on letting it take action on the server, or will it be for informational purpose only?
Dedicated servers | VPS | VPS resellers | cPanel/WHM resellers | shared hosting - SmokyHosts.com
DirectAdmin | Unlimited space | Unmetered traffic | PHP | NodeJS - 0frills.com
To be honest, I don't know the market for this yet. pretty much an experiment at this stage.
I feel there is some space for this between traditional self-managed server panels and expensive fully managed end-to-end solutions like Heroku.
For me personally at this moment, its about simplifying deployments, like saying
"given this git repo and domain, setup a webserver with auto SSL, setup postgres and make this code run ensuring the right env vars/credentials have been passed to the app."and just having it happen on one or more servers.
My Personal Blog | Currently Building LoadMyCode
you are absolutely correct! what I found so far is that general models don't seem to be great at this, so I might put in some time fine tuning the models. I am trying a few things using LLaMA-Factory
Yeah it does take action if you ask it to install packages or configure certain things. it is very broad and not fine tuned enough so it can be a bit rough.
My Personal Blog | Currently Building LoadMyCode
"I want to host wordpress". And all hell brakes loose.
Hostinger (a very large host) invest heavily into home-built GPT for unmanaged servers. They try to solve few problems with that:
Congrats. A little bit similar to Warp, but that's more a terminal tool.
Kind of a neat concept. I'm curious which AI you're using on the backend? Google used to have very nice free tiers, but now it's just the new Gemma 3N model with a high free tier allowance. Supposedly that model is designed to run locally, even on Android, so that probably transfers into some not so great results.
Gather 1000 machines under control.
Send as a botnet for 1 BTC.
Daniel fan club 😎 affbrr
we have been experimenting with quite a few, but currently,
we divide it into three, Router(weak), plan/execute(strong) & summarizer(medium)
for the weak model we use 'DeepSeek R1 0528 Qwen3 8B Distill', its plenty fast to figure out what and where and is used to replace any sensitive content with placeholders before it is sent out.
for the strong model, we use Gemini 2.5 Pro, but its quite expensive as you would know but its the only one that seems to be a little useful.
for the summarizer, we use Gemini 2.5 Flash, not too cheap nor too expensive but good enough for what it does.
we also use 'Qwen3-Embedding-0.6B' for generating embeddings (this was pretty much a no brainer decision), I have also used this on production workloads and its actually very good so would definitely recommend it if anyone is looking to generate embeddings.
Most of it is plug and play, so plan is to allow you to bring your own key/inference-server if required.
My Personal Blog | Currently Building LoadMyCode
Are you running your own instance using llama.cpp or something similar or are there people out there hosting the free/open source models?
Both the distill and the embedding model are hosted by ourselves.
My Personal Blog | Currently Building LoadMyCode