LOL. Is making me reconsider not cancelling the CHI one and letting this one go - a couple of days left, to decide. Hmm. For the sake of $6 - times they are a tough!
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural. It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
@skorous said:
If you don't mind, did you put in a lot of tickets? I've heard of some people getting blocked but it was because they tended to put in dozens of tickets.
In a year, I had only 2 tickets, one of which told me to create a VirMach related to the back migration. My last ticket was more than 2 months ago about broken SSL and panel on shared hosting. Since then, this hosting has ceased to work at all. And there was no response to the ticket. All I wanted was for the cpanel to be restored and I could take a backup of several sites hanging on a shared hosting.
Also, what is "incomprehensible letters compiled by an incomprehensible algorithm"?
I meant emails saying that I did something, I most likely violated something, but VirMach will not tell me what kind of violation it is and if I'm not sure, I should contact them and repent. I guess this is case about buying and selling accounts. Considering that I have never done these stupid things, I wrote a post here and forgot about it. I don't have time to prove the obvious, and besides, I don't know how to prove it. It is enough to look at the history of the account to understand that it is not from this cohort. However, VirMach trusts the broken algorithms of WHMCS and therefore sends nonsense to customers. And then blocked the ability to open critical tickets.
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural. It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
@skorous said:
If you don't mind, did you put in a lot of tickets? I've heard of some people getting blocked but it was because they tended to put in dozens of tickets.
In a year, I had only 2 tickets, one of which told me to create a VirMach related to the back migration. My last ticket was more than 2 months ago about broken SSL and panel on shared hosting. Since then, this hosting has ceased to work at all. And there was no response to the ticket. All I wanted was for the cpanel to be restored and I could take a backup of several sites hanging on a shared hosting.
Also, what is "incomprehensible letters compiled by an incomprehensible algorithm"?
I meant emails saying that I did something, I most likely violated something, but VirMach will not tell me what kind of violation it is and if I'm not sure, I should contact them and repent. I guess this is case about buying and selling accounts. Considering that I have never done these stupid things, I wrote a post here and forgot about it. I don't have time to prove the obvious, and besides, I don't know how to prove it. It is enough to look at the history of the account to understand that it is not from this cohort. However, VirMach trusts the broken algorithms of WHMCS and therefore sends nonsense to customers. And then blocked the ability to open critical tickets.
Your name looks familiar. I haven't read everything an I'm only skimming but based on my memory you're multi-account related or related to sniping deals maybe, not putting in a lot of tickets (as in you, @Unicom.) The email should've listed all the potential reasons.
@vgood said:
strange events always occur non-stop with different problems in this @VirMach service
1. My VPS in November said it was suspended even though the usage had not reached 1TB, while the limit on the package was 6 TB.
December 1, the suspension is automatically removed and the bandwidth reset becomes 0
suddenly I checked on December 3, it was again suspended with the reason that it exceeded bandwidth usage. even though I haven't used the VPS for anything, it's very funny. how does a VPS consume 6 TB in just 1 day. messed up... really messed up...
I remember your name as well, my guess is you'd be the type of person to have your password as Dog123456
Just a vague guess. And the 6TB probably can get used up as quickly as like half a day on outbound attack/botnet. Especially if you got it early on a bandwidth reset, your VM is most likely hacked.
@localhost said:
Can someone please confirm active locations of Virmach servers?
Amsterdam NL, Frankfurt DE, Secaucus NJ, Chicago IL, Atlanta GA, Tampa, FL, Miami FL, Dallas TX, Denver CO, Phoenix AZ, Los Angeles CA, San Jose CA, Seattle WA, Tokyo JP.
@vgood said:
strange events always occur non-stop with different problems in this @VirMach service
1. My VPS in November said it was suspended even though the usage had not reached 1TB, while the limit on the package was 6 TB.
December 1, the suspension is automatically removed and the bandwidth reset becomes 0
suddenly I checked on December 3, it was again suspended with the reason that it exceeded bandwidth usage. even though I haven't used the VPS for anything, it's very funny. how does a VPS consume 6 TB in just 1 day. messed up... really messed up...
I remember your name as well, my guess is you'd be the type of person to have your password as Dog123456
Just a vague guess. And the 6TB probably can get used up as quickly as like half a day on outbound attack/botnet. Especially if you got it early on a bandwidth reset, your VM is most likely hacked.
@vgood said:
strange events always occur non-stop with different problems in this @VirMach service
1. My VPS in November said it was suspended even though the usage had not reached 1TB, while the limit on the package was 6 TB.
December 1, the suspension is automatically removed and the bandwidth reset becomes 0
suddenly I checked on December 3, it was again suspended with the reason that it exceeded bandwidth usage. even though I haven't used the VPS for anything, it's very funny. how does a VPS consume 6 TB in just 1 day. messed up... really messed up...
I remember your name as well, my guess is you'd be the type of person to have your password as Dog123456
Just a vague guess. And the 6TB probably can get used up as quickly as like half a day on outbound attack/botnet. Especially if you got it early on a bandwidth reset, your VM is most likely hacked.
@vgood said:
strange events always occur non-stop with different problems in this @VirMach service
1. My VPS in November said it was suspended even though the usage had not reached 1TB, while the limit on the package was 6 TB.
December 1, the suspension is automatically removed and the bandwidth reset becomes 0
suddenly I checked on December 3, it was again suspended with the reason that it exceeded bandwidth usage. even though I haven't used the VPS for anything, it's very funny. how does a VPS consume 6 TB in just 1 day. messed up... really messed up...
I remember your name as well, my guess is you'd be the type of person to have your password as Dog123456
Just a vague guess. And the 6TB probably can get used up as quickly as like half a day on outbound attack/botnet. Especially if you got it early on a bandwidth reset, your VM is most likely hacked.
I thought he had changed it to strong password...
I don't remember what actually went down it was a genuine guess but the more I think about it, makes sense that we've already spoken about it if I vaguely remember him as being someone who didn't have a secure password (or I could just be misremembering, there's always that.)
Anyway with that said if he did actually already change it to something secure it wouldn't actually un-infect it unless there was a reinstall, or maybe he also changed VNC password to something not secure and kept that one the same?
@vgood said:
strange events always occur non-stop with different problems in this @VirMach service
1. My VPS in November said it was suspended even though the usage had not reached 1TB, while the limit on the package was 6 TB.
December 1, the suspension is automatically removed and the bandwidth reset becomes 0
suddenly I checked on December 3, it was again suspended with the reason that it exceeded bandwidth usage. even though I haven't used the VPS for anything, it's very funny. how does a VPS consume 6 TB in just 1 day. messed up... really messed up...
I remember your name as well, my guess is you'd be the type of person to have your password as Dog123456
Just a vague guess. And the 6TB probably can get used up as quickly as like half a day on outbound attack/botnet. Especially if you got it early on a bandwidth reset, your VM is most likely hacked.
I thought he had changed it to strong password...
I don't remember what actually went down it was a genuine guess but the more I think about it, makes sense that we've already spoken about it if I vaguely remember him as being someone who didn't have a secure password (or I could just be misremembering, there's always that.)
Anyway with that said if he did actually already change it to something secure it wouldn't actually un-infect it unless there was a reinstall, or maybe he also changed VNC password to something not secure and kept that one the same?
can I ask,how you collect VPS disk usage(IOPS), will it count fuse mount as native disk too?
@skorous said:
If you don't mind, did you put in a lot of tickets? I've heard of some people getting blocked but it was because they tended to put in dozens of tickets.
In a year, I had only 2 tickets, one of which told me to create a VirMach related to the back migration. My last ticket was more than 2 months ago about broken SSL and panel on shared hosting. Since then, this hosting has ceased to work at all. And there was no response to the ticket. All I wanted was for the cpanel to be restored and I could take a backup of several sites hanging on a shared hosting.
Also, what is "incomprehensible letters compiled by an incomprehensible algorithm"?
I meant emails saying that I did something, I most likely violated something, but VirMach will not tell me what kind of violation it is and if I'm not sure, I should contact them and repent. I guess this is case about buying and selling accounts. Considering that I have never done these stupid things, I wrote a post here and forgot about it. I don't have time to prove the obvious, and besides, I don't know how to prove it. It is enough to look at the history of the account to understand that it is not from this cohort. However, VirMach trusts the broken algorithms of WHMCS and therefore sends nonsense to customers. And then blocked the ability to open critical tickets.
Your name looks familiar. I haven't read everything an I'm only skimming but based on my memory you're multi-account related or related to sniping deals maybe, not putting in a lot of tickets (as in you, @Unicom.) The email should've listed all the potential reasons.
I have no idea what sniper deals are. Once again: I have never dealt with buying and selling accounts. I only have one account and I have no idea what you were thinking there. I also indicated this in automatic ticket #863057. Don't you think that if you suspect me of something, then you must prove it, or at least show arguments so that I can somehow defend my position? Now it looks disgusting.
However, limiting the ability of clients to report a broken service is beyond my understanding. Whatever the reasons are. First, make the service available, or give the option to pick up the backup, and then deal with what you want.
I remind you that for 3 days Shared-1 has not shown signs of life. 2 months cpanel, ftp and ssl does not work for it. My Ticket #789783 about this was ignored and after that I was not allowed to create tickets at all. I can't pick up backups to deploy websites on another VPS. I can't create a ticket about this due to your restrictions.
full here: https://lowendspirit.com/discussion/comment/113305/#Comment_113305
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural. It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural. It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
@Unicom said: or: A network error occurred during your login request. Please try again. If this condition persists, contact your network service provider.
IP 31.222.203.3 does not respond to pings.
traceroute from Chicago dies at 45.92.192.125
traceroute to 31.222.203.3 (31.222.203.3), 30 hops max, 60 byte packets
2 66.63.167.42.static.quadranet.com (66.63.167.42) 19.428 ms 19.434 ms 19.455 ms
3 104.129.29.248.static.quadranet.com (104.129.29.248) 46.053 ms 46.059 ms 46.059 ms
4 ae28-616.cr1-chi1.ip4.gtt.net (98.124.187.57) 1.710 ms 1.753 ms 1.792 ms
5 ae12.cr10-chi1.ip4.gtt.net (213.254.230.162) 4.132 ms 1.887 ms 1.913 ms
6 * be3257.ccr41.ord03.atlas.cogentco.com (154.54.11.241) 1.497 ms 1.549 ms
7 be2766.ccr42.ord01.atlas.cogentco.com (154.54.46.177) 1.627 ms be2765.ccr41.ord01.atlas.cogentco.com (154.54.45.17) 1.514 ms 1.600 ms
8 be2717.ccr21.cle04.atlas.cogentco.com (154.54.6.222) 22.450 ms be2718.ccr22.cle04.atlas.cogentco.com (154.54.7.130) 13.258 ms be2717.ccr21.cle04.atlas.cogentco.com (154.54.6.222) 22.382 ms
9 be2889.ccr41.jfk02.atlas.cogentco.com (154.54.47.50) 19.137 ms 18.998 ms be2890.ccr42.jfk02.atlas.cogentco.com (154.54.82.246) 18.968 ms
10 be2967.rcr22.ewr03.atlas.cogentco.com (154.54.30.114) 20.390 ms be2273.rcr21.ewr03.atlas.cogentco.com (154.54.83.206) 19.485 ms be3020.rcr22.ewr03.atlas.cogentco.com (154.54.41.114) 19.636 ms
11 be2131.nr51.b045024-0.ewr03.atlas.cogentco.com (154.24.3.122) 19.321 ms be2040.nr51.b045024-0.ewr03.atlas.cogentco.com (154.24.37.42) 19.402 ms 19.852 ms
12 38.104.74.130 (38.104.74.130) 20.045 ms 20.234 ms 19.760 ms
13 * border1-po1-bbnet1.nyj004.pnap.net (216.52.95.46) 19.399 ms 19.023 ms
14 dedipath-48.border1.nyj004.pnap.net (74.201.164.150) 19.080 ms dedicontrol-1.border2.nyj004.pnap.net (64.74.240.242) 21.889 ms 21.827 ms
15 45.92.192.125 (45.92.192.125) 1506.885 ms 1506.860 ms 1506.893 ms
16 * * *
17 * * *
@taizi said: can I ask,how you collect VPS disk usage(IOPS), will it count fuse mount as native disk too?
It only counts data directly related to the LVM/local. I see around 10MB/s average write, but at average size of 4KB. It's not that fancy, as in it uses reliable pre-existing open source software that grabs it directly from /proc but based on the information I've pieced together from what you've said so far then obviously when it's getting copied over to the local disk then it would count for the writes.
How does your monitor calculate? I see it has the same 10MB/s average write.
So if it's saying 37 io/s and 10MB/s for write, would you say then that average request size is 278.77KB instead of 4KB? You mentioned rclone, what cache mode? What swap configuration? I see it at 17% swap so are you sure this is accounted for by your monitor? Do you have any information/data on what occurred during the rclone process? As in quantity of files, total size, and duration.
Or here's a potentially interesting rhetorical question set of questions:
Unless the node you're on is heavily bottlenecked on I/O, which we can agree it wouldn't be if the "disk abuse detector" is randomly counting everyone as what's essentially claimed to be around 80x more than actual usage, why would a Gen4 NVMe only be doing 10MB/s on 280KB~ average request size when it's capable of doing, even on the lower-end, 1500Mbps sequential writes at 256KB, and coincidentally (?) about 200MB/s for random 4KB? And why is it not even reaching that? What happens if the average wait time is instead of being much lower, 1.18MS and why? What do you believe could happen if instead of being able to bundle the requests, it has to keep waiting in spikes if it's also relying on external factors performing just as well? How does caching and swapping work in all this with the VM configuration and rclone settings and other factors? What happens if we take into account potential write amplification from garbage collection and the potential problems that arise as a result of virtualization overhead?
Once again, rhetorical. Some of them have simple answers, a few of them I won't even know the answer until looking into it further. The point I'm trying to make is that it's more complicated than just immediately assuming there's a bug in our monitoring. Could it be? Sure. Could it be many other things? Yes.
@Unicom said: I have no idea what sniper deals are. Once again: I have never dealt with buying and selling accounts. I only have one account and I have no idea what you were thinking there. I also indicated this in automatic ticket #863057.
You're not going to get any responses here if this is how you interpret them. Let's go over it again but highlight a few things:
Your name looks familiar. I haven't read everything an I'm only skimming but based on my memory you're multi-account related or related to sniping deals maybe, not putting in a lot of tickets (as in you, @Unicom.) The email should've listed all the potential reasons.
You mention buying and selling accounts, this was not brought up in my comment.
It's possible you only have one account, a third party message board is not meant to be used for support so naturally I don't have all your account notes and details, if you don't then you don't and my quick attempt at a guess was incorrect.
Just because ticket IDs or other information is provided doesn't mean I'll immediately check it
@Unicom said: Don't you think that if you suspect me of something, then you must prove it, or at least show arguments so that I can somehow defend my position? Now it looks disgusting.
You want me to do that here? We already went over this, if you really want I'll share all the notes and details here. Otherwise just wait for the ticket to be processed.
@Unicom said: However, limiting the ability of clients to report a broken service is beyond my understanding. Whatever the reasons are. First, make the service available, or give the option to pick up the backup, and then deal with what you want.
If you're speaking of the shared hosting, we're aware and have been from the start and it's actively being worked on. The status page was created and updated, but it's re-occurring and there's several other ongoing things right now. We can either flood the network statuses and leave them open so it shows up in that view, or for older issues that may re-occur the older posts are there for reference under "resolved" the first time they were handled. Anyway, there's been some time since I began writing this response since the main focus is working out the issues, so since then it's been updated since the issue got further out of control.
If a service is found to be broken and it's only affecting your service, once your account issue ticket is handled we can always sort that out. If it's a widespread issue, it's not necessary for you to be able to report it since we will always get other reports and if we don't we still have monitoring.
@Unicom said: I remind you that for 3 days Shared-1 has not shown signs of life. 2 months cpanel, ftp and ssl does not work for it.
I'll come back with more information once we stabilize the node, but our monitoring definitely shows "signs of life." I know there's been errors and it obviously has not been fully usable. I probably count 50% uptime over last 72 hours and maybe 20% halfway slightly usable, 20% not usable, and 10% actual fully offline outage (this last part is about to skyrocket.)
Regarding 2 months comments, this is only based on what I've seen in most cases where we've received similar reports, so once again, I'll provide more information once I can look into it, but the current guess is this:
Most likely cPanel issue would have been very very early on while we were still transitioning the servers, and it was resolved. There is a small chance that maybe specifically yours has another issue, we'll see.
FTP was corrected several weeks ago as well. I couldn't find any reports around that time, I believe it was based on our own checks.
Auto SSL has always been a little iffy in some situations, to fix it, manually running it on cPanel may be required and if you can't or didn't log in at the time, then it might not fix itself due to how the queues are processed.
Also, there's only so much we can do for free plans. If we have to take into account all the potential support overhead, we just can't offer them in the first place. I'm not saying you should expect it to be permanently broken or not have it fixed for major issues, just that when the issues overlap with things that are affecting everyone, it will generally be fixed without requiring a support ticket. I'm not 100% sure yet if this is the case for yours or not, but obviously at the time when you made the ticket, I closed it because I thought it was already addressed globally. Maybe I'm wrong, we'll see.
SJCZ007 was a nightmare to get back up and stable. I think that node has a bunch of VMs that have low memory and large swap files, and I basically had to go through one by one booting them back up, waiting for it to do its thing, monitor, and then move to the next. Many of them were still also just booting directly into kernel panic on the 384MB VMs. With everything else going on at the same time it wasn't very fun.
NYCB009 is just toast in other ways. It might be related to a few things I was looking into but it's difficult to look into it when it keeps going into overload loops. I don't think it's related to any foul play but it did most recently end up dying and waiting on RH. I think CPU couldn't handle it and shut itself off and firmware is also having problems in that the power on function glitches out, and of course another glitch caused by firmware update. Like certain version on certain boards in certain configurations means it just doesn't listen to some configurations until the firmware is updated but to update the firmware, it has to do a firmware update so it's like rolling the dice.
@VirMach said: You want me to do that here? We already went over this, if you really want I'll share all the notes and details here.
I can't speak for everybody else but I've been kinda curious ever since.
@VirMach said: I know it sounds harsh but if everyone else could see why your account is in this state I'm sure they would be more understanding. I don't want to say anything else publicly for your own privacy.
@taizi said: can I ask,how you collect VPS disk usage(IOPS), will it count fuse mount as native disk too?
It only counts data directly related to the LVM/local. I see around 10MB/s average write, but at average size of 4KB. It's not that fancy, as in it uses reliable pre-existing open source software that grabs it directly from /proc but based on the information I've pieced together from what you've said so far then obviously when it's getting copied over to the local disk then it would count for the writes.
I've been stressed over the "80 IOPS" limit for a long time because I have no idea how to measure it.
Here you said "average size of 4KB".
Does this mean I can safely read/write large files at 240KB/s speed?
I have Seafile installed for syncing photos from my phones, with daily rclone backup to elsewhere.
So far I didn't set any speed limits, and it hasn't triggered abuse script.
However, I'm happy to limit it further to be on the safe side.
@Unicom okay I got the server back up so very quickly, let's test out the three issues you've had and see if it's been broken. I'm performing all these as a client, as in the same way you could do it.
Clicked login to cPanel, it logged in. Looks like your disk space is at 100.07% utilization. It also does show this properly on WHMCS, but says the file usage amount out of "Unlimited" so I guess we have to look into that, assuming you know the max for your plan though the total usage number is correct.
Of course the login wouldn't have worked all the time last 3 days, I'll look and see if you mentioned anything else over the last 3 months here.
Second issue, SSL. Looks like an error last time it ran December 3rd, one of the domains doesn't resolve properly. Another one doesn't. One of them maybe didn't run. This is where I have to go into WHM for the last one, I'm reading the logs, it's because you're out of disk space I think. Not enough space for the temporary file to validate.
Okay so yeah, I think I was correct to close it in this case but let me know.
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural. It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
@VirMach said: You want me to do that here? We already went over this, if you really want I'll share all the notes and details here.
where can we discuss this if you blocked me from using the ticket system?
Otherwise just wait for the ticket to be processed.
Considering how you handle tickets, I could wait forever. I closed the previous ticket after 2 months of ignoring it. You say that you are getting data from other sources (and this is obviously true) however, the ticket with the message that ssl is not working was ignored, and the problem was not solved. Unfortunately, it is impossible to solve the problem through cpanel. I tried several times to log into cpanel to make backups, but the panel didn't work. Unfortunately, I didn't have time to create another ticket or write here on the forum and check cpanel's work every day. Until 3 days ago everything died and I found that I was denied access to tickets. So I had to write here about these problems because there is nowhere else.
@VirMach said: I see it has the same 10MB/s average write.
after some tries, I found it was caused by my binance bot, it will get the latest price and write into a JSON file, but after i shut it down,the 10MB/s write disappeared...
but I run my bot since a month ago, and it is normal, and no abuse warning. after a period of time I use rclone, it started warning me(like one week later)
@VirMach said: You mentioned rclone, what cache mode? What swap configuration?
no cache,no swap.I combine rclone+juicefs to mount,juicefs helps me splitting files to 4MB each block,also provided disk cache option,it will use LRU to clear unuseful cache when the disk is full(<5GB)
in my juicefs status, it shows avg 25ops/sec and avg 18transcations/sec.
@Civalo said: @VirMach My previous tick was merged with #218112, which is awaiting the billing dept, but you have already dealt with the billing issue yourself. Can you look at #218112 and get someone on it? I've been waiting since September.
Thanks
John
Dedicated server issue would've been resolved yesterday if you had a ticket that mentioned a dedicated server in the title or description. I think previous issue was that it didn't and it got overlooked, and I remember looking over this and fixing that (hopefully, or thought I did.)
If you opened another ticket and it got merged, that sounds like another potential obstacle.
I have not had time to address any of these for the past week, I delegated them to our other team member. I'll try to create some time today to finally close these out, sorry for it taking so long.
@VirMach I know you are kept busy. But, can I get an update on this? It was supposed to be a simple install of Alma Linux, instead of Centos. It's all been put on ticket 218112, but seems like nothing is being done at this point. Been waiting since September.
Thanks for you time.
John
Hey John,
If you don't mind getting your hands dirty, CentOS can actually be converted to Alma! Make sure you're running CentOS 8 and just follow these steps:


Comments
LOL. Is making me reconsider not cancelling the CHI one and letting this one go - a couple of days left, to decide. Hmm. For the sake of $6 - times they are a tough!
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural.
It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
In a year, I had only 2 tickets, one of which told me to create a VirMach related to the back migration. My last ticket was more than 2 months ago about broken SSL and panel on shared hosting. Since then, this hosting has ceased to work at all. And there was no response to the ticket. All I wanted was for the cpanel to be restored and I could take a backup of several sites hanging on a shared hosting.
I meant emails saying that I did something, I most likely violated something, but VirMach will not tell me what kind of violation it is and if I'm not sure, I should contact them and repent. I guess this is case about buying and selling accounts. Considering that I have never done these stupid things, I wrote a post here and forgot about it. I don't have time to prove the obvious, and besides, I don't know how to prove it. It is enough to look at the history of the account to understand that it is not from this cohort. However, VirMach trusts the broken algorithms of WHMCS and therefore sends nonsense to customers. And then blocked the ability to open critical tickets.
Yay! Someone killed the luser/abuser on ATLZ010.VIRM.AC.
Not too drastic!

In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural.
It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
1070 @MichaelCee is available to answer tickets for a fee to help you clear the backlog
Your name looks familiar. I haven't read everything an I'm only skimming but based on my memory you're multi-account related or related to sniping deals maybe, not putting in a lot of tickets (as in you, @Unicom.) The email should've listed all the potential reasons.
I remember your name as well, my guess is you'd be the type of person to have your password as Dog123456
Just a vague guess. And the 6TB probably can get used up as quickly as like half a day on outbound attack/botnet. Especially if you got it early on a bandwidth reset, your VM is most likely hacked.
Some other pages.
Facilities - https://virmach.com/datacenters/
Network - https://virmach.com/network/
Chatbot status + status combo page - https://statusbot.virm.ac/
I thought he had changed it to strong password...
Should disable passes and use keys.
The Yeti has left the building.
I don't remember what actually went down it was a genuine guess but the more I think about it, makes sense that we've already spoken about it if I vaguely remember him as being someone who didn't have a secure password (or I could just be misremembering, there's always that.)
Anyway with that said if he did actually already change it to something secure it wouldn't actually un-infect it unless there was a reinstall, or maybe he also changed VNC password to something not secure and kept that one the same?
can I ask,how you collect VPS disk usage(IOPS), will it count fuse mount as native disk too?
I have no idea what sniper deals are. Once again: I have never dealt with buying and selling accounts. I only have one account and I have no idea what you were thinking there. I also indicated this in automatic ticket #863057. Don't you think that if you suspect me of something, then you must prove it, or at least show arguments so that I can somehow defend my position? Now it looks disgusting.
However, limiting the ability of clients to report a broken service is beyond my understanding. Whatever the reasons are. First, make the service available, or give the option to pick up the backup, and then deal with what you want.
I remind you that for 3 days Shared-1 has not shown signs of life. 2 months cpanel, ftp and ssl does not work for it. My Ticket #789783 about this was ignored and after that I was not allowed to create tickets at all. I can't pick up backups to deploy websites on another VPS. I can't create a ticket about this due to your restrictions.
full here: https://lowendspirit.com/discussion/comment/113305/#Comment_113305
@Unicom FYI: https://nycb009.virm.ac:2083/ loads up fine for me, to login prompt.
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural.
It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
yes now login page opened, but the authentication still fails.
or:
A network error occurred during your login request. Please try again. If this condition persists, contact your network service provider.Hmm. I don't know what to do because my service provider has forbidden me to notify him of any problems and I have to do it on a third party forum.
I suspect that your compatriots on that server are hammering it (This is why we can't have nice things!):
https://status.virm.ac/?s=62d9fd34e694aa2901450f49
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural.
It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
https://nycb009.virm.ac:2083 does not open for me ether.
IP 31.222.203.3 does not respond to pings.
traceroute from Chicago dies at 45.92.192.125
EDIT: It's up now at 2 PM PST
Died again
@VirMach
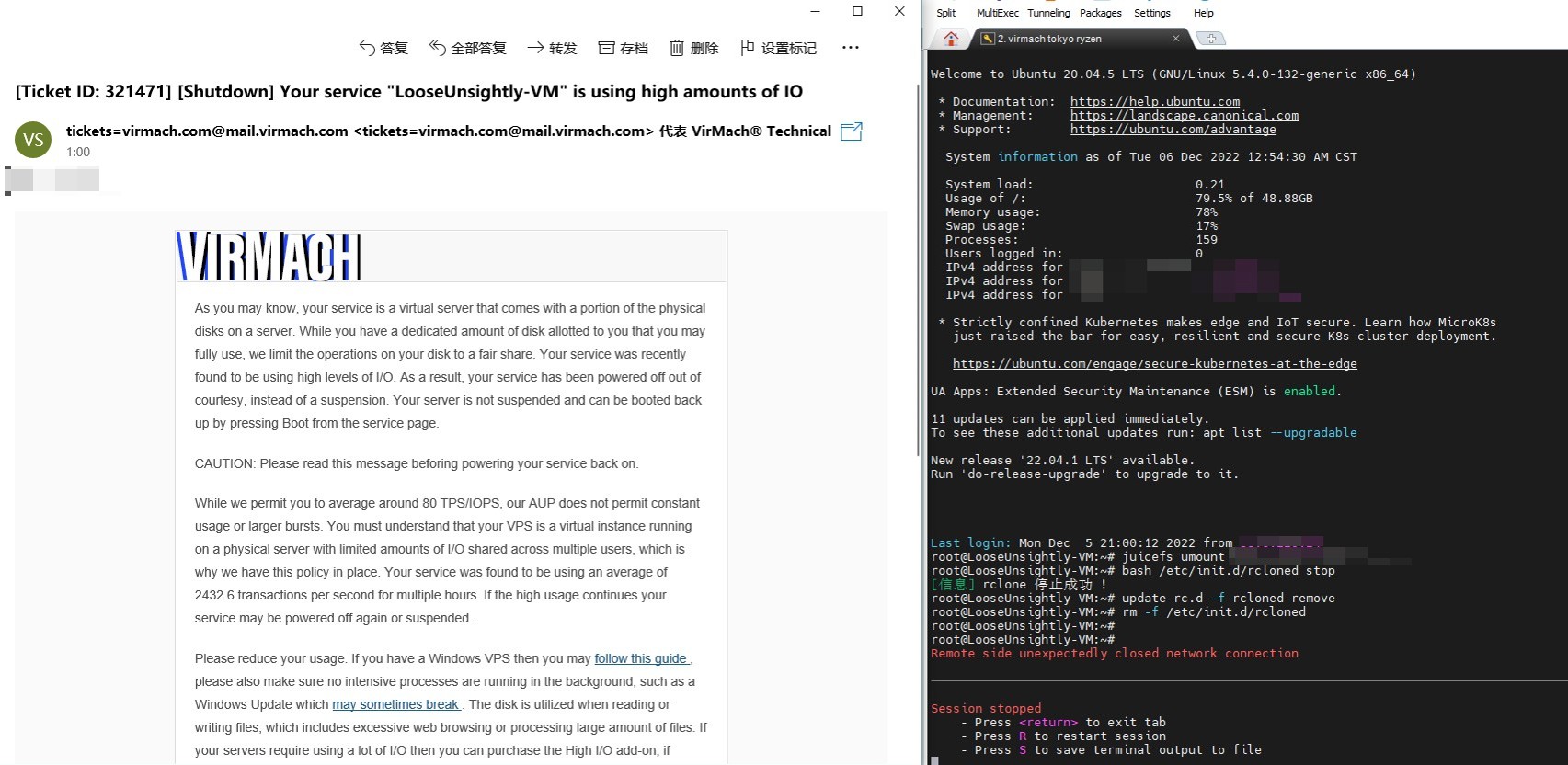
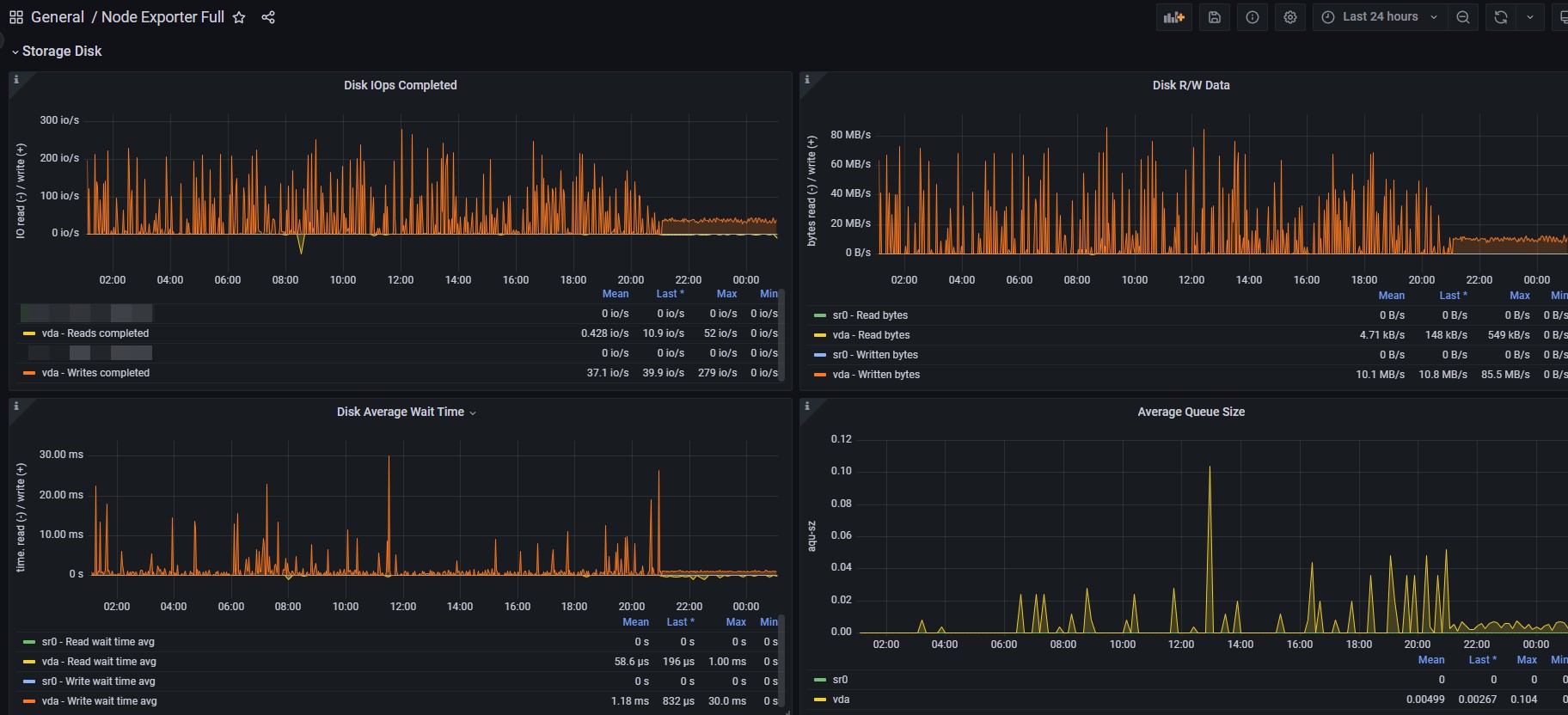
I bet your disk-abuser detector system has bug
now I close the rclone completely, lets see will I receive warning tomorrow
btw, nice merge, let "abuser" can't receive their reply forever because some new ticket merged into
It only counts data directly related to the LVM/local. I see around 10MB/s average write, but at average size of 4KB. It's not that fancy, as in it uses reliable pre-existing open source software that grabs it directly from /proc but based on the information I've pieced together from what you've said so far then obviously when it's getting copied over to the local disk then it would count for the writes.
How does your monitor calculate? I see it has the same 10MB/s average write.
So if it's saying 37 io/s and 10MB/s for write, would you say then that average request size is 278.77KB instead of 4KB? You mentioned rclone, what cache mode? What swap configuration? I see it at 17% swap so are you sure this is accounted for by your monitor? Do you have any information/data on what occurred during the rclone process? As in quantity of files, total size, and duration.
Or here's a potentially interesting rhetorical question set of questions:
Unless the node you're on is heavily bottlenecked on I/O, which we can agree it wouldn't be if the "disk abuse detector" is randomly counting everyone as what's essentially claimed to be around 80x more than actual usage, why would a Gen4 NVMe only be doing 10MB/s on 280KB~ average request size when it's capable of doing, even on the lower-end, 1500Mbps sequential writes at 256KB, and coincidentally (?) about 200MB/s for random 4KB? And why is it not even reaching that? What happens if the average wait time is instead of being much lower, 1.18MS and why? What do you believe could happen if instead of being able to bundle the requests, it has to keep waiting in spikes if it's also relying on external factors performing just as well? How does caching and swapping work in all this with the VM configuration and rclone settings and other factors? What happens if we take into account potential write amplification from garbage collection and the potential problems that arise as a result of virtualization overhead?
Once again, rhetorical. Some of them have simple answers, a few of them I won't even know the answer until looking into it further. The point I'm trying to make is that it's more complicated than just immediately assuming there's a bug in our monitoring. Could it be? Sure. Could it be many other things? Yes.
You're not going to get any responses here if this is how you interpret them. Let's go over it again but highlight a few things:
Your name looks familiar. I haven't read everything an I'm only skimming but based on my memory you're multi-account related or related to sniping deals maybe, not putting in a lot of tickets (as in you, @Unicom.) The email should've listed all the potential reasons.
You want me to do that here? We already went over this, if you really want I'll share all the notes and details here. Otherwise just wait for the ticket to be processed.
If you're speaking of the shared hosting, we're aware and have been from the start and it's actively being worked on. The status page was created and updated, but it's re-occurring and there's several other ongoing things right now. We can either flood the network statuses and leave them open so it shows up in that view, or for older issues that may re-occur the older posts are there for reference under "resolved" the first time they were handled. Anyway, there's been some time since I began writing this response since the main focus is working out the issues, so since then it's been updated since the issue got further out of control.
If a service is found to be broken and it's only affecting your service, once your account issue ticket is handled we can always sort that out. If it's a widespread issue, it's not necessary for you to be able to report it since we will always get other reports and if we don't we still have monitoring.
I'll come back with more information once we stabilize the node, but our monitoring definitely shows "signs of life." I know there's been errors and it obviously has not been fully usable. I probably count 50% uptime over last 72 hours and maybe 20% halfway slightly usable, 20% not usable, and 10% actual fully offline outage (this last part is about to skyrocket.)
Regarding 2 months comments, this is only based on what I've seen in most cases where we've received similar reports, so once again, I'll provide more information once I can look into it, but the current guess is this:
Also, there's only so much we can do for free plans. If we have to take into account all the potential support overhead, we just can't offer them in the first place. I'm not saying you should expect it to be permanently broken or not have it fixed for major issues, just that when the issues overlap with things that are affecting everyone, it will generally be fixed without requiring a support ticket. I'm not 100% sure yet if this is the case for yours or not, but obviously at the time when you made the ticket, I closed it because I thought it was already addressed globally. Maybe I'm wrong, we'll see.
SJCZ007 was a nightmare to get back up and stable. I think that node has a bunch of VMs that have low memory and large swap files, and I basically had to go through one by one booting them back up, waiting for it to do its thing, monitor, and then move to the next. Many of them were still also just booting directly into kernel panic on the 384MB VMs. With everything else going on at the same time it wasn't very fun.
NYCB009 is just toast in other ways. It might be related to a few things I was looking into but it's difficult to look into it when it keeps going into overload loops. I don't think it's related to any foul play but it did most recently end up dying and waiting on RH. I think CPU couldn't handle it and shut itself off and firmware is also having problems in that the power on function glitches out, and of course another glitch caused by firmware update. Like certain version on certain boards in certain configurations means it just doesn't listen to some configurations until the firmware is updated but to update the firmware, it has to do a firmware update so it's like rolling the dice.
I can't speak for everybody else but I've been kinda curious ever since.
I've been stressed over the "80 IOPS" limit for a long time because I have no idea how to measure it.
Here you said "average size of 4KB".
Does this mean I can safely read/write large files at 240KB/s speed?
I have Seafile installed for syncing photos from my phones, with daily rclone backup to elsewhere.
So far I didn't set any speed limits, and it hasn't triggered abuse script.
However, I'm happy to limit it further to be on the safe side.
best of "yoursunny lore" by Google AI 🤣 affbrr
@Unicom okay I got the server back up so very quickly, let's test out the three issues you've had and see if it's been broken. I'm performing all these as a client, as in the same way you could do it.
Clicked login to cPanel, it logged in. Looks like your disk space is at 100.07% utilization. It also does show this properly on WHMCS, but says the file usage amount out of "Unlimited" so I guess we have to look into that, assuming you know the max for your plan though the total usage number is correct.
Of course the login wouldn't have worked all the time last 3 days, I'll look and see if you mentioned anything else over the last 3 months here.
Second issue, SSL. Looks like an error last time it ran December 3rd, one of the domains doesn't resolve properly. Another one doesn't. One of them maybe didn't run. This is where I have to go into WHM for the last one, I'm reading the logs, it's because you're out of disk space I think. Not enough space for the temporary file to validate.
Okay so yeah, I think I was correct to close it in this case but let me know.
VirMach on fire with answering questions so I will ask too!
GIFF BACK TPAZ002 aka TPAZ005 aka WHERE IS MY VPS THAT I NEVER USED?!
Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural.
It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
When nagging Virmach enters Socrates mode and begins to throw rhetorical questions
Ontario Dildo Inspector
Ontario Dildo Inspector
where can we discuss this if you blocked me from using the ticket system?
Considering how you handle tickets, I could wait forever. I closed the previous ticket after 2 months of ignoring it. You say that you are getting data from other sources (and this is obviously true) however, the ticket with the message that ssl is not working was ignored, and the problem was not solved. Unfortunately, it is impossible to solve the problem through cpanel. I tried several times to log into cpanel to make backups, but the panel didn't work. Unfortunately, I didn't have time to create another ticket or write here on the forum and check cpanel's work every day. Until 3 days ago everything died and I found that I was denied access to tickets. So I had to write here about these problems because there is nowhere else.
after some tries, I found it was caused by my binance bot, it will get the latest price and write into a JSON file, but after i shut it down,the 10MB/s write disappeared...
but I run my bot since a month ago, and it is normal, and no abuse warning. after a period of time I use rclone, it started warning me(like one week later)
no cache,no swap.I combine rclone+juicefs to mount,juicefs helps me splitting files to 4MB each block,also provided disk cache option,it will use LRU to clear unuseful cache when the disk is full(<5GB)
in my juicefs status, it shows avg 25ops/sec and avg 18transcations/sec.
Ontario Dildo Inspector
Hey John,
If you don't mind getting your hands dirty, CentOS can actually be converted to Alma! Make sure you're running CentOS 8 and just follow these steps:
sudo -idnf updaterebootwget https://raw.githubusercontent.com/AlmaLinux/almalinux-deploy/master/almalinux-deploy.shYou can then run
vim almalinux-deploy.shto make sure everything looks fine.
chmod -v +x almalinux-deploy.sh./almalinux-deploy.sh(this takes a LONG TIME)
rebootand you should be greeted with a lovely new Alma 8 install! Thanks for submitting your ticket to the LowEndHelpdesk!