@hosthatch said:
We've always advertised GB and TB, never GiB or TiB.
I really do not see the moral/ethical dilemma here. If you purchased a plan with 8TB bandwidth and it accidentally came with 9TB, and we changed it to 8TB an year later, it wouldn't really be as big of a scandal?
Not the fact you've changed this is a problem imo but if this has been 9TB for 2 years and now it'll be 8TB, a short notice would be nice that this will happen and is an intended change.
Understandable, we will add a note about this in the panel
Honestly, i understand why they created the new terms but we'd all be using kilo-, mega-, etc... for so long that only half the people converted. As a result it's still confusing when you see TB how the other side is using it. They should've made the stupid drive manufacturers use a new term since they were the ones corrupting it
@Mumbly said: Oslo:
IPv6 work, but only one address (no matter how many of them I add). And after some time even this one die.
It seems like it's not about old/new addresses actually. I tryed few things, different setups, etc, but no luck. I can't explain to myself why is that. Everything's seems correct on the VPS side.
I'm seeing the same issue in Oslo + Stockholm. After a reboot, IPv6 works fine for few seconds, then breaks again. Have you been able to figure out a solution yet?
@Mumbly said: Oslo:
IPv6 work, but only one address (no matter how many of them I add). And after some time even this one die.
It seems like it's not about old/new addresses actually. I tryed few things, different setups, etc, but no luck. I can't explain to myself why is that. Everything's seems correct on the VPS side.
I'm seeing the same issue in Oslo + Stockholm. After a reboot, IPv6 works fine for few seconds, then breaks again. Have you been able to figure out a solution yet?
Whatever I did it, it didn't work. I went through all settings numerous times. Even identical setup copied from Vienna VPS (same package, same ISO, everything the same, just different /64 of course) which work in Vienna flawlessly didn't help in Oslo. Nothing, nada, zilch... helped. Also support (where I tryed to be helpful as much as possible) after initial response didn't came back to me.
So at some point I ditched ISO install, closed support ticket, went with reinstall from the template (& back to eth0) and then things started to work.
If you're willing to, I suggest you to reinstall Oslo VPS from the template not from mounted ISO and you may see improvement.
@Brueggus said: I'm seeing the same issue in Oslo + Stockholm. After a reboot, IPv6 works fine for few seconds, then breaks again. Have you been able to figure out a solution yet?
Question: are you using .1 as at least one of your addresses on the interface?
@Mumbly said: Oslo:
IPv6 work, but only one address (no matter how many of them I add). And after some time even this one die.
It seems like it's not about old/new addresses actually. I tryed few things, different setups, etc, but no luck. I can't explain to myself why is that. Everything's seems correct on the VPS side.
I'm seeing the same issue in Oslo + Stockholm. After a reboot, IPv6 works fine for few seconds, then breaks again. Have you been able to figure out a solution yet?
So it works for a while and starts to timeout?
And when you restart the interface, it works again and times out again soon after?
@Mumbly said: Oslo:
IPv6 work, but only one address (no matter how many of them I add). And after some time even this one die.
It seems like it's not about old/new addresses actually. I tryed few things, different setups, etc, but no luck. I can't explain to myself why is that. Everything's seems correct on the VPS side.
I'm seeing the same issue in Oslo + Stockholm. After a reboot, IPv6 works fine for few seconds, then breaks again. Have you been able to figure out a solution yet?
So it works for a while and starts to timeout?
And when you restart the interface, it works again and times out again soon after?
Yep, exactly. But Oslo appears to be stable now, I'm still having issues in Stockholm, though.
@skorous said: Question: are you using .1 as at least one of your addresses on the interface?
@Mumbly said: Oslo:
IPv6 work, but only one address (no matter how many of them I add). And after some time even this one die.
It seems like it's not about old/new addresses actually. I tryed few things, different setups, etc, but no luck. I can't explain to myself why is that. Everything's seems correct on the VPS side.
I'm seeing the same issue in Oslo + Stockholm. After a reboot, IPv6 works fine for few seconds, then breaks again. Have you been able to figure out a solution yet?
So it works for a while and starts to timeout?
And when you restart the interface, it works again and times out again soon after?
Yes, exactly. After interface restart it worked for few minutes.
I am not sure about @Brueggus case, but in my case only one from several added address worked (ie 2a0d:xx.xx.xx::d from example above) and then died which was even more confusing. All the others were dead from the beginning.
@Mumbly said: up /sbin/ifconfig ens3 inet6 add 2a0d:xx.xx.xx::d/64
Have you tried adding preferred_lft 0 to the end like:
up /sbin/ifconfig ens3 inet6 add 2a0d:xx.xx.xx::d/64 preferred_lft 0
I haven't gotten around to fixing the IPv6 issues/breakage in many of my VMs as yet.
Previously, I had to use the ::2 address as the ::1 didn't support rDNS. So I was just using the ::2 with the appropriate /48 gateway and didn't have issues.
Now it looks like I have to use the ::1 but it HAS to be the primary preferred global interface (so the rest have to have the preferred_lft 0 setting - can anyone confirm if my understanding is correct? It'll save me some time when I get around to fixing things.
@nullnothere said: Now it looks like I have to use the ::1 but it HAS to be the primary preferred global interface (so the rest have to have the preferred_lft 0 setting
I have servers on the new panel which work fine and don't have ::1 as their preferred address. This shouldn't be an issue.
@nullnothere said: Now it looks like I have to use the ::1 but it HAS to be the primary preferred global interface (so the rest have to have the preferred_lft 0 setting
I have servers on the new panel which work fine and don't have ::1 as their preferred address. This shouldn't be an issue.
@Mumbly said: Yes, of course as 2a0d:xx.xx.xx::1/64 is default setup anyway.
Default for template users perhaps.
@nullnothere said: Now it looks like I have to use the ::1 but it HAS to be the primary preferred global interface (so the rest have to have the preferred_lft 0 setting - can anyone confirm if my understanding is correct? It'll save me some time when I get around to fixing things.
I can say that my experience has been the same. Until I made ::1 the primary it would work for about ten seconds and then stop.
When you reinstall a "legacy VM", the current process is to remove it and create a new VM using the new system.
This does not mean that existing live volumes are shrunk, which is being suggested in multiple places (the other one being LET). If we shrink an existing volume, that would render an existing VMs useless, as can be assumed from your earlier comment in reply to the person who cannot boot up their VM.
Such comments usually lead to a bunch of tickets asking us whether we are about to lose people's data by shrinking their existing VMs, which obviously isn't happening, so please excuse my annoyedness.
does this mean the reinstalled VM will be converted from GiB to GB? Aka less storage than before.
Yes it does.
This should have really been mentioned in the email or the control panel. Customers wouldn't expect that a "reinstall" button would reduce the amount of disk space on the VPS.
I reinstalled one of my VMs to see if it'd get rid of the 'legacy' tag and see if any new features pop up, and now I can't restore my disk backup image because the disk is too small:
@nullnothere said: Now it looks like I have to use the ::1 but it HAS to be the primary preferred global interface (so the rest have to have the preferred_lft 0 setting - can anyone confirm if my understanding is correct? It'll save me some time when I get around to fixing things.
I can say that my experience has been the same. Until I made ::1 the primary it would work for about ten seconds and then stop.
It's routed IPv6 so in theory you should only have to add the ::1 address to your network configuration - all traffic to the entire subnet is routed to your VPS. It must be the ::1 address because that's the address the traffic is routed to, so just adding others won't work.
@Daniel said:
I reinstalled one of my VMs to see if it'd get rid of the 'legacy' tag and see if any new features pop up, and now I can't restore my disk backup image because the disk is too small:
I guess a good reason to avoid an upgrade. As a bit of an aside, does anyone know what extra features non legacy systems have over migrated ones (apart from smaller partitions ), and does booting from ISO in any way trigger the upgrade/shrink, though I'd suspect not as you might just be doing a recovery intervention.
Hm, previously for my "Legacy" VPS it stated under networking: Your server is currently using our legacy internal networking. We recommend you to upgrade to our new private VLAN networking by clicking the button below. Please note that this will remove your existing internal interface.
I don't see that text/button anylonger, now I only see the Reinstall option.
I don't mind losing some GiB to GB bytes, but since I installed from ISO, I don't want to reinstall everything right now, will have to wait a few weeks.
Does this mean that the private VLAN will not be available until I reinstall?
(Do I need to use that "Reinstall" option, or just mount ISO and reinstall?)
@flips said:
Does this mean that the private VLAN will not be available until I reinstall?
(Do I need to use that "Reinstall" option, or just mount ISO and reinstall?)
Reinstall once using the reinstall button and after this your VM is in their new format and you can start over with an ISO installation.
When you reinstall a "legacy VM", the current process is to remove it and create a new VM using the new system.
This does not mean that existing live volumes are shrunk, which is being suggested in multiple places (the other one being LET). If we shrink an existing volume, that would render an existing VMs useless, as can be assumed from your earlier comment in reply to the person who cannot boot up their VM.
Such comments usually lead to a bunch of tickets asking us whether we are about to lose people's data by shrinking their existing VMs, which obviously isn't happening, so please excuse my annoyedness.
does this mean the reinstalled VM will be converted from GiB to GB? Aka less storage than before.
Yes it does.
This should have really been mentioned in the email or the control panel. Customers wouldn't expect that a "reinstall" button would reduce the amount of disk space on the VPS.
I reinstalled one of my VMs to see if it'd get rid of the 'legacy' tag and see if any new features pop up, and now I can't restore my disk backup image because the disk is too small:
I ended up getting my VM up and running again. This was an NVMe VM rather than a storage VM though.
It took a while.
What I ended up doing was restoring the 10 GiB backup to a different HostHatch 10 GiB VM (or I guess I could have restored it to a local VM). It took around 30 mins:
because the other VM was in Amsterdam, and the connection between HH Los Angeles and HH Amsterdam is quite slow:
Booted into GParted Live
oh no it would have been a VERY tight squeeze to resize the 9.41GiB partition to <= 9GiB (new disk is ~9.3GiB and I want to to allow for ~300MB swap)
Mounted it, ran ncdu to find stuff to delete, deleted them
Went back into GParted to resize the partition to 9 GiB
Booted into Clonezilla again and ran it in remote source mode
Booted the original VM into Clonezilla and ran it in remote dest mode
Cloned the partition over the network
Finally it's back.
This would have been completely unnecessary if HostHatch had just been more upfront about the disk being resized on reinstall. I know they've added a notice now, but there wasn't one when I reinstalled this VM, and their support told me they could not "un-migrate" my VM or increase its disk size to the original amount, hence the long-winded workaround of restoring elsewhere to reduce the backup disk image size.
They really should have allowed people who migrated before the reduced disk space notice was added to revert back to the legacy system, as a gesture of goodwill.


Comments
Understandable, we will add a note about this in the panel")
Honestly, i understand why they created the new terms but we'd all be using kilo-, mega-, etc... for so long that only half the people converted. As a result it's still confusing when you see TB how the other side is using it. They should've made the stupid drive manufacturers use a new term since they were the ones corrupting it
I'm seeing the same issue in Oslo + Stockholm. After a reboot, IPv6 works fine for few seconds, then breaks again. Have you been able to figure out a solution yet?
dnscry.pt - Public DNSCrypt resolvers hosted by LowEnd providers • Need a free NAT LXC? -> https://microlxc.net/
Whatever I did it, it didn't work. I went through all settings numerous times. Even identical setup copied from Vienna VPS (same package, same ISO, everything the same, just different /64 of course) which work in Vienna flawlessly didn't help in Oslo. Nothing, nada, zilch... helped. Also support (where I tryed to be helpful as much as possible) after initial response didn't came back to me.
So at some point I ditched ISO install, closed support ticket, went with reinstall from the template (& back to eth0) and then things started to work.
If you're willing to, I suggest you to reinstall Oslo VPS from the template not from mounted ISO and you may see improvement.
Question: are you using .1 as at least one of your addresses on the interface?
Do you mean ::1?
Yes, of course as 2a0d:xx.xx.xx::1/64 is default setup anyway.
As example:
So it works for a while and starts to timeout?
And when you restart the interface, it works again and times out again soon after?
Yep, exactly. But Oslo appears to be stable now, I'm still having issues in Stockholm, though.
Yes, Sir.
dnscry.pt - Public DNSCrypt resolvers hosted by LowEnd providers • Need a free NAT LXC? -> https://microlxc.net/
Yes, exactly. After interface restart it worked for few minutes.
I am not sure about @Brueggus case, but in my case only one from several added address worked (ie 2a0d:xx.xx.xx::d from example above) and then died which was even more confusing. All the others were dead from the beginning.
Have you tried adding preferred_lft 0 to the end like:
up /sbin/ifconfig ens3 inet6 add 2a0d:xx.xx.xx::d/64 preferred_lft 0I haven't gotten around to fixing the IPv6 issues/breakage in many of my VMs as yet.
Previously, I had to use the ::2 address as the ::1 didn't support rDNS. So I was just using the ::2 with the appropriate /48 gateway and didn't have issues.
Now it looks like I have to use the ::1 but it HAS to be the primary preferred global interface (so the rest have to have the
preferred_lft 0setting - can anyone confirm if my understanding is correct? It'll save me some time when I get around to fixing things.Thanks in advance...
I have servers on the new panel which work fine and don't have ::1 as their preferred address. This shouldn't be an issue.
dnscry.pt - Public DNSCrypt resolvers hosted by LowEnd providers • Need a free NAT LXC? -> https://microlxc.net/
Yeah I'm not sure about that either.
I never use
::1on any of my servers, anywhere.Default for template users perhaps.
I can say that my experience has been the same. Until I made ::1 the primary it would work for about ten seconds and then stop.
Why not use ::1 then?
I am now. I wasn't then.
This should have really been mentioned in the email or the control panel. Customers wouldn't expect that a "reinstall" button would reduce the amount of disk space on the VPS.
I reinstalled one of my VMs to see if it'd get rid of the 'legacy' tag and see if any new features pop up, and now I can't restore my disk backup image because the disk is too small:

It's routed IPv6 so in theory you should only have to add the
::1address to your network configuration - all traffic to the entire subnet is routed to your VPS. It must be the ::1 address because that's the address the traffic is routed to, so just adding others won't work.Daniel15 | https://d.sb/. List of all my VPSes: https://d.sb/servers
dnstools.ws - DNS lookups, pings, and traceroutes from 30 locations worldwide.
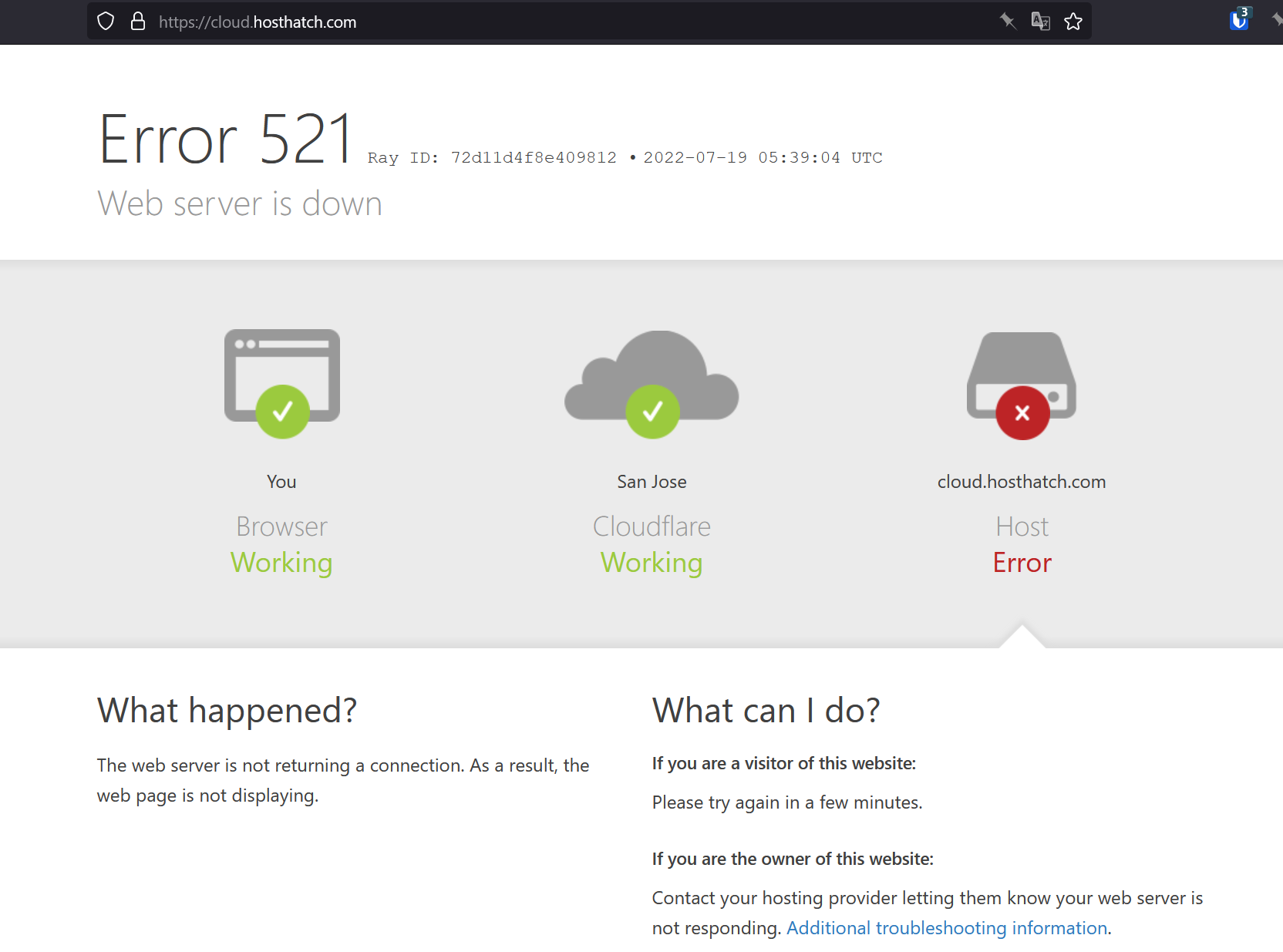
their cloud panel is currently down.
I bench YABS 24/7/365 unless it's a leap year.
3.5 hours later, it's still down
Daniel15 | https://d.sb/. List of all my VPSes: https://d.sb/servers
dnstools.ws - DNS lookups, pings, and traceroutes from 30 locations worldwide.
could they have been ddosed by snowflakes?
I bench YABS 24/7/365 unless it's a leap year.
All of their panels have been down but now they're up again for me.
I guess a good reason to avoid an upgrade. As a bit of an aside, does anyone know what extra features non legacy systems have over migrated ones (apart from smaller partitions") ), and does booting from ISO in any way trigger the upgrade/shrink, though I'd suspect not as you might just be doing a recovery intervention.
), and does booting from ISO in any way trigger the upgrade/shrink, though I'd suspect not as you might just be doing a recovery intervention.
Good question. I would wish to know this too - possibly from @hosthatch
I reserve the right to license all of my content under: CC BY-NC-ND. Whatever happens on this forum should stay on this forum.
@hosthatch Will existing customers on "legacy" disks be forced to re-install the VM anytime soon?
Cloudron.io - Lovely self hosted management suite [aff]
HetrixTools - Highly recommended uptime monitor [aff]
Hm, previously for my "Legacy" VPS it stated under networking:")
Your server is currently using our legacy internal networking. We recommend you to upgrade to our new private VLAN networking by clicking the button below. Please note that this will remove your existing internal interface.
I don't see that text/button anylonger, now I only see the Reinstall option.
I don't mind losing some GiB to GB bytes, but since I installed from ISO, I don't want to reinstall everything right now, will have to wait a few weeks.
Does this mean that the private VLAN will not be available until I reinstall?
(Do I need to use that "Reinstall" option, or just mount ISO and reinstall?)
Reinstall once using the reinstall button and after this your VM is in their new format and you can start over with an ISO installation.
Have the Italy and Spain locations been upgraded to 10Gbit/s actually? The docs still say 1Gbit/s for these locations.
Support answer:
I ended up getting my VM up and running again. This was an NVMe VM rather than a storage VM though.
It took a while.
What I ended up doing was restoring the 10 GiB backup to a different HostHatch 10 GiB VM (or I guess I could have restored it to a local VM). It took around 30 mins:
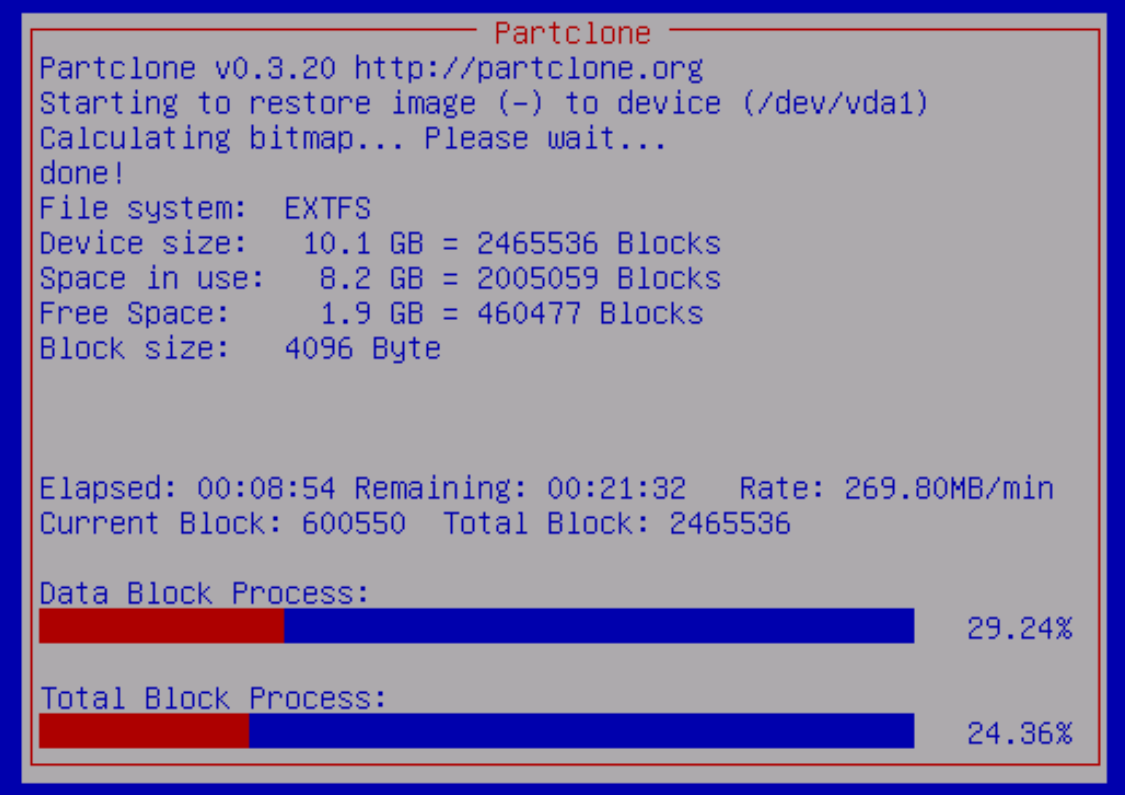
because the other VM was in Amsterdam, and the connection between HH Los Angeles and HH Amsterdam is quite slow:
Booted into GParted Live
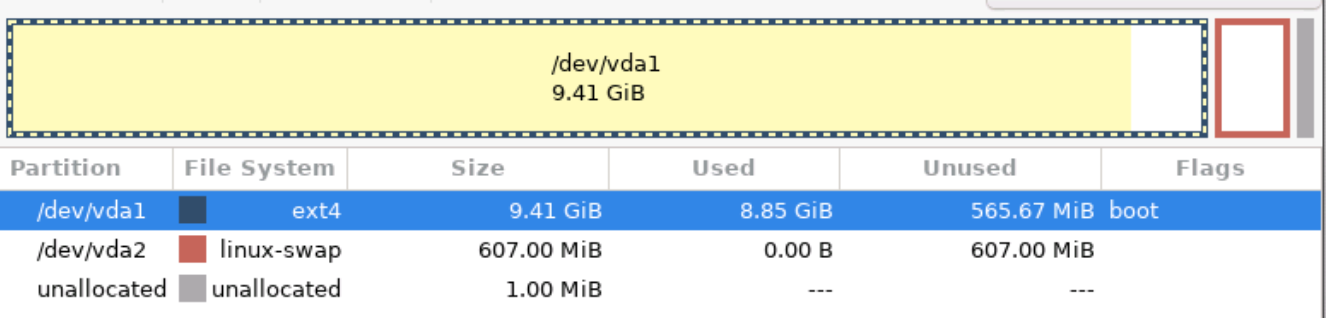
oh no it would have been a VERY tight squeeze to resize the 9.41GiB partition to <= 9GiB (new disk is ~9.3GiB and I want to to allow for ~300MB swap)
Mounted it, ran
ncduto find stuff to delete, deleted themWent back into GParted to resize the partition to 9 GiB
Booted into Clonezilla again and ran it in remote source mode
Booted the original VM into Clonezilla and ran it in remote dest mode
Cloned the partition over the network
Finally it's back.
This would have been completely unnecessary if HostHatch had just been more upfront about the disk being resized on reinstall. I know they've added a notice now, but there wasn't one when I reinstalled this VM, and their support told me they could not "un-migrate" my VM or increase its disk size to the original amount, hence the long-winded workaround of restoring elsewhere to reduce the backup disk image size.
They really should have allowed people who migrated before the reduced disk space notice was added to revert back to the legacy system, as a gesture of goodwill.
Daniel15 | https://d.sb/. List of all my VPSes: https://d.sb/servers
dnstools.ws - DNS lookups, pings, and traceroutes from 30 locations worldwide.
Anyone else’s LA location services been up and down like a yo-yo recently?
Yes
I already got multiple hetrixtool down report from LA
25 Jul 19:11 25 Jul 19:12 1min Errors
25 Jul 13:46 25 Jul 13:47 1min Errors
25 Jul 11:40 25 Jul 11:41 1min Errors
24 Jul 06:54 24 Jul 06:55 1min Errors
23 Jul 20:22 23 Jul 20:24 2min Errors
23 Jul 18:13 23 Jul 18:16 3min Errors
23 Jul 11:23 23 Jul 11:24 1min Errors
18 Jul 10:21 19 Jul 18:45 1d 8hr 24min Errors