In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural. It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
@jcn50 said:
Ah, I found it on this status page, overloaded crap showing as green/online :
Lots of I/O abuse recently. Well it's been happening for a while but not to a level that was extremely concerning. This particular one was someone we previously mass suspended who just made new accounts and ordered again.
Many of the rest are people running Docker very specifically on Ubuntu 20 and usually 1GB or less memory.
Tokyo's mainly the usual, one service running like a dozen different applications and having 300+ people accessing it simultaneously. We have alerts set up and I pretty much notice it within 10 minutes of it happening, but in this case I must have not been paying attention. By the time I noticed it was already overloading heavily and I finally just gave up and power cycled it.
We pay a good amount per month for this monitoring service. For the past two months probably, maybe longer, it's been constant set of 502 errors, even on our end. They don't seem to care, support doesn't really answer either. I've been slowly working on making our own monitoring system instead but with everything else it's too much work for it to be completed any time soon.
You'll never guess which company bought them out.
Basically just be prepared to load it 3 times and wait like a minute. This is the same monitoring system that fully went down on Black Friday and I had to do manual deals since black friday flash sale relies on it.
@VirMach said: We pay a good amount per month for this monitoring service. > For the past two months probably, maybe longer, it's been constant set of 502 errors, even on our end. They don't seem to care, support doesn't really answer either. I've been slowly working on making our own monitoring system instead but with everything else > it's too much work for it to be completed any time soon.
We use it in a very specific way and there's nothing that would fit all our requirements. We have to just make it ourselves. The uptime monitoring portion doesn't matter at all and that's really easy to get done.
We have very specific alerts for the weirdest most specific things that no one would usually want, and this also keeps track of things like network usage per VPS in a useful way, aggregates usage by locations, shows very specific graphs for memory, processor, load. Process list, temperatures, disk health. I already know how to do all of it because I happen to have used the same applications it utilizes in the background directly, and know how to get it done, but it's just definitely a multiple day focusing on it type of project.
I also tend to try to mush projects together when I see any similarities so this means I'm not just working on a replacement for this, but I want to also integrate some of the things we used this for directly into it.
I can finally talk about Phoenix but the story is insanely long so I'm just going to do it this way.
DediPath --> Remove the Dedi and that's where we ended up. Initially = good. They put us under a sub-brand. Until we actually needed to contact them when servers died. While that was happening, something else happened. Miscommunication on their end, we were contacted about a billing issue except the higher-up that we had never spoken to previously decided to just send one email from their other brand/his work email and not the right brand/system. He said some things, we missed it, although he never provided an appropriate timeline. We thought there was an outage, he stepped in aggressively and was more concerned about this new issue he created even though it was their fault and we were immediately cooperating. He kept changing their demands, we immediately agreed (even though we were in the right) and he still managed to drag it out (that was the multiple week outage, they completely refused to do anything without his seal of approval.) We got busy and couldn't get them to complete our requests since all communication dragged out, so a good portion of the delays were our fault at this point. Finally we decided to just pull everything as we did not trust them, and that dragged out as well a few more weeks waiting on them. If PHXZ004 was in Los Angeles it would have returned online within a day (based on my educated guess on what it is, we'll find out in a few days.)
Keep in mind this is a 250~ word summary of the original 4000+ word essay. Any questions or requested elaboration, let me know.
@VirMach
I submitted a suspension appeal in Ticket #619341
I paid the relevant fees as required, but because I did not receive the email notification, my server was suspended again (only 5 hours later)
I am not sure what happened to the server that caused the abnormal traffic. I cannot operate it immediately after the server is restored to normal, so please reinstall the system and restore it
@core said: @VirMach
I submitted a suspension appeal in Ticket #619341
I paid the relevant fees as required, but because I did not receive the email notification, my server was suspended again (only 5 hours later)
I am not sure what happened to the server that caused the abnormal traffic. I cannot operate it immediately after the server is restored to normal, so please reinstall the system and restore it
If you're in a rush to receive a response, I can provide a rushed response. You won't like the response though. Any time a suspension appeal is taking a long time it means I really know I have to deny the appeal but waiting to see if I can convince myself otherwise.
New York City is sinking into the ocean?
Host node: NYCB031
We cannot load the controls for your service at this time.
This could either mean:
A) It took too long to load.
B) The server controls have been automatically disabled due to an anomoly.
C) The server could be offline, in which case we have already been notified.
@FrankZ said: Up at NYCB013. Down on NYCB032 & NYCB45.
Maybe a bad switch ?
Somebody unplugged a rack ?
EDIT: Down on NYCB013 now also but it went down 35 min after the first two.
At this point it's a conspiracy. It seems like NYC network always goes down on holidays. It's being worked on. Came back for a bit.
Low man on the totem pole DC guy pissed off at having to work all the holidays randomly pulling network cables ?
No worries. I have redundant servers in Miami and Chicago.
@FrankZ said: Low man on the totem pole DC guy pissed off at having to work all the holidays randomly pulling network cables ?
From my experience the people who work holidays are usually subs who aren't as agile with the hardware and aisles. Could have been working on something in the opposite rack while bumping this one accidentally and taking the network down.
(This has actually happened at another company I used to work at, but it was only a fat twin taken down)
Unfortunately it's looking to be another one of those situations. If we had the usual tech there, it could be resolved.
It's one of the switches. I've lost count, but we've sent in copious brand new replacements, replaced specific parts inside these switches, and switched the switch switch switch. Can't access it, so someone has to go there with serial and troubleshoot. That someone is not the current tech. The current tech did bring it online twice but it doesn't last.
We also ordered in two new switches from our provider who was going to preconfigure them (it's a different brand, I already barely know how to work the ones we have and defer networking usually, but this one I definitely know nothing on.) However there were unforeseen delays on their end. Since the re-re-placement had the broken module replaced with a brand new one, we suspected it would last long enough for the two new switches to come in (I think this was mid-August when ordered.)
I'm trying to take inventory right now and look for a 3rd/4th replacement as well as parts to overnight to NYC at this point in case troubleshooting doesn't go well but that would hit a holiday weekend nightmare scenario.
@FrankZ said: Low man on the totem pole DC guy pissed off at having to work all the holidays randomly pulling network cables ?
We did actually get them to pull a networking cable as a simple potential solution since we couldn't get into the switch to disable it. That was the second time it came online but it didn't help.


Comments
Now he gonna troll me with
Â:-DThanks for deleting the March one :-)
Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png
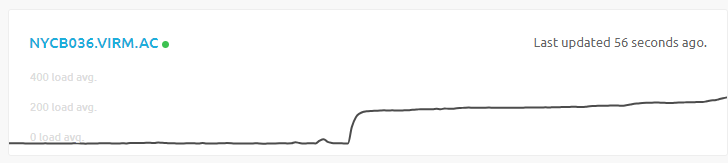
What anomoly ???.. There is nothing on the status page. This is NYCB036.
💩 VirCrap 💩
Ah, I found it on this status page, overloaded crap showing as green/online :
:
💩 VirCrap 💩
@Virmach : sorry, had to open emergency Ticket #252006
💩 VirCrap 💩
EMERGENCY
I bench YABS 24/7/365 unless it's a leap year.
That'll be 15 bucks, sir.
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural.
It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
💩 VirCrap 💩
HTTP ERROR 502 on the status page: https://status.virm.ac/ Merry Xmas
Merry Xmas 
💩 VirCrap 💩
Lots of I/O abuse recently. Well it's been happening for a while but not to a level that was extremely concerning. This particular one was someone we previously mass suspended who just made new accounts and ordered again.
Many of the rest are people running Docker very specifically on Ubuntu 20 and usually 1GB or less memory.
Tokyo's mainly the usual, one service running like a dozen different applications and having 300+ people accessing it simultaneously. We have alerts set up and I pretty much notice it within 10 minutes of it happening, but in this case I must have not been paying attention. By the time I noticed it was already overloading heavily and I finally just gave up and power cycled it.
We pay a good amount per month for this monitoring service. For the past two months probably, maybe longer, it's been constant set of 502 errors, even on our end. They don't seem to care, support doesn't really answer either. I've been slowly working on making our own monitoring system instead but with everything else it's too much work for it to be completed any time soon.
You'll never guess which company bought them out.
Basically just be prepared to load it 3 times and wait like a minute. This is the same monitoring system that fully went down on Black Friday and I had to do manual deals since black friday flash sale relies on it.
There are self-hosted APPs for this~
No?
💩 VirCrap 💩
Sounds familiar.
https://microlxc.net/
We use it in a very specific way and there's nothing that would fit all our requirements. We have to just make it ourselves. The uptime monitoring portion doesn't matter at all and that's really easy to get done.
We have very specific alerts for the weirdest most specific things that no one would usually want, and this also keeps track of things like network usage per VPS in a useful way, aggregates usage by locations, shows very specific graphs for memory, processor, load. Process list, temperatures, disk health. I already know how to do all of it because I happen to have used the same applications it utilizes in the background directly, and know how to get it done, but it's just definitely a multiple day focusing on it type of project.
I also tend to try to mush projects together when I see any similarities so this means I'm not just working on a replacement for this, but I want to also integrate some of the things we used this for directly into it.
I can finally talk about Phoenix but the story is insanely long so I'm just going to do it this way.
DediPath --> Remove the Dedi and that's where we ended up. Initially = good. They put us under a sub-brand. Until we actually needed to contact them when servers died. While that was happening, something else happened. Miscommunication on their end, we were contacted about a billing issue except the higher-up that we had never spoken to previously decided to just send one email from their other brand/his work email and not the right brand/system. He said some things, we missed it, although he never provided an appropriate timeline. We thought there was an outage, he stepped in aggressively and was more concerned about this new issue he created even though it was their fault and we were immediately cooperating. He kept changing their demands, we immediately agreed (even though we were in the right) and he still managed to drag it out (that was the multiple week outage, they completely refused to do anything without his seal of approval.) We got busy and couldn't get them to complete our requests since all communication dragged out, so a good portion of the delays were our fault at this point. Finally we decided to just pull everything as we did not trust them, and that dragged out as well a few more weeks waiting on them. If PHXZ004 was in Los Angeles it would have returned online within a day (based on my educated guess on what it is, we'll find out in a few days.)
Keep in mind this is a 250~ word summary of the original 4000+ word essay. Any questions or requested elaboration, let me know.
they should be all consolidated in LAX which would be a win-win situation
I bench YABS 24/7/365 unless it's a leap year.
IIAC they already were.
@VirMach
I submitted a suspension appeal in Ticket #619341
I paid the relevant fees as required, but because I did not receive the email notification, my server was suspended again (only 5 hours later)
I am not sure what happened to the server that caused the abnormal traffic. I cannot operate it immediately after the server is restored to normal, so please reinstall the system and restore it
@VirMach I guess I will loose this cute IP : 31.222.202.22X then
XD
https://microlxc.net/
If you're in a rush to receive a response, I can provide a rushed response. You won't like the response though. Any time a suspension appeal is taking a long time it means I really know I have to deny the appeal but waiting to see if I can convince myself otherwise.
I really liked that block too. I kept it longer than I should, it was technically one of our more expensive ones.
New York City is sinking into the ocean?
Host node: NYCB031
We cannot load the controls for your service at this time.
This could either mean:
A) It took too long to load.
B) The server controls have been automatically disabled due to an anomoly.
C) The server could be offline, in which case we have already been notified.
best of "yoursunny lore" by Google AI 🤣 affbrr
Up at NYCB013. Down on NYCB032 & NYCB45.
Maybe a bad switch ?
Somebody unplugged a rack ?
EDIT: Down on NYCB013 now also but it went down 35 min after the first two.
At this point it's a conspiracy. It seems like NYC network always goes down on holidays. It's being worked on. Came back for a bit.
spooky, mulder. thanks for the update and quick update on site. i closed my ticket to avoid needing to pay the troll toll
Low man on the totem pole DC guy pissed off at having to work all the holidays randomly pulling network cables ?
No worries. I have redundant servers in Miami and Chicago.
I should go to sleep
From my experience the people who work holidays are usually subs who aren't as agile with the hardware and aisles. Could have been working on something in the opposite rack while bumping this one accidentally and taking the network down.
(This has actually happened at another company I used to work at, but it was only a fat twin taken down)
TTL exceeded on the IPs so it looked like it may be router related.
Maybe router is rebooting and dropped IP announcements. Checked route-views and nothing to my /24 currently.
Wonder if a tech was working on the opposite rack
PS: Sorry for the low-end monday morning quarterback on the guessing, I can't turn it off. Prob why work likes me.
Unfortunately it's looking to be another one of those situations. If we had the usual tech there, it could be resolved.
It's one of the switches. I've lost count, but we've sent in copious brand new replacements, replaced specific parts inside these switches, and switched the switch switch switch. Can't access it, so someone has to go there with serial and troubleshoot. That someone is not the current tech. The current tech did bring it online twice but it doesn't last.
We also ordered in two new switches from our provider who was going to preconfigure them (it's a different brand, I already barely know how to work the ones we have and defer networking usually, but this one I definitely know nothing on.) However there were unforeseen delays on their end. Since the re-re-placement had the broken module replaced with a brand new one, we suspected it would last long enough for the two new switches to come in (I think this was mid-August when ordered.)
I'm trying to take inventory right now and look for a 3rd/4th replacement as well as parts to overnight to NYC at this point in case troubleshooting doesn't go well but that would hit a holiday weekend nightmare scenario.
We did actually get them to pull a networking cable as a simple potential solution since we couldn't get into the switch to disable it. That was the second time it came online but it didn't help.