@willie said:
Do you need someone to go to the SJ data center and mess with stuff? I know people in that area who might be available.
This may actually be helpful if it can be coordinated. The issue we've noticed that manifests itself into the problem we're observing has essentially for the most part been the CPU getting "loose" due to the way the pins work on the AM4 platform. Basically, the thermal paste creates a good adhesion -- too good, and it ends up creating some kind of "suction" where the heatsink is prone to pulling off the CPU since the motherboard has a weak latch. During shipping, the pins get pulled up and I assume they have a loose connection, which results in the server going "offline" in the same manner it would if the CPU was missing or has a bent pin. The motherboard is still getting power so the BMC chip continues functioning, but we're unable to boot it back up.
This also tends to also occur if we have a bad DIMM, but we already sorted out memory errors with RAM swaps in San Jose. It's still a possibility. It could also technically be a cable but that's less likely to just boot back up.
One co-morbidity seems to be high CPU usage. Past a threshold, I assume in some way related to the wattage or boosting, is when it seems to occur. These servers in San Jose still don't have the switch configuration changes, meaning naturally higher CPU usage just to keep the NIC going, not necessarily any abuse or overselling.
I'm going to try pushing a switch configuration change (VLANs) with our provider. One main problem we've been having is that they were set up very messy with this specific provider which caused a lot of grief in the past, as port numbers were mislabeled, so it extended the whole process and caused a lot of outages which we'd want to avoid this time around. That would reduce CPU usage, reduce the chances of it occurring again for now, and facilitate migrations to Los Angeles.
The problem with doing a CPU swap that we've noticed is that DC hands, even if they're willing, tend to have a hard time removing the CPU as it gets stuck to the heatsink, and it's very easy to screw it up and bend the CPU pins. We've had this happen before and of the DC hands aren't quick to admit it so it ends up with the server going from slightly unusable to fully broken.
@VirMach said: This is completely out of our hands and we're frustrated as well. I've bumped up the issue for our datacenter partner but it doesn't seem to be a priority for them and/or the module developers. Of course we could just walk away but that's not exactly going to fix anything and would only create more headache for everyone.
software or hardware modules?
Software.
@Mason said: @VirMach I know it may be tempting to go balls to the walls like you traditionally do, but I seriously hope you consider taking it easy this Black Friday / Cyber Monday. Get all that behind the scenes work done, stabilize all the post-migration stuff, and finally get some rest because you deserve it man.
We'll have everything wrapped up by then and I probably do not want to do a BF sale but we may have to end up doing it. Here, I'll promise one thing and make sure to remind me of it a week before BF: if the consensus is that we haven't gone everything stable & done, let me know and we'll definitely cancel the BF sale.
Between the broken website, a year plus of not having our main non-sale product (licensed Windows VPS), the migrations/transition to Ryzen, the dedicated server fiasco, and many other factors, we haven't exactly been meeting revenue targets. While it's nowhere near a "critical" stage and we're doing fine and will continue doing fine, we do technically need to recoup the costs associated with purchasing a ton of brand new hardware and at the very least it would help with our continued expansion if we had another big boost of revenue to purchase more Ryzen sooner.
I'm still definitely considering other options just to avoid doing a BF sale. As much as I love doing a crazy sale, I would personally love to instead take some time off this year.
@seanho said:
Just wanted to say I'm glad the mess is looking more manageable; great job pulling through!
Thank you, I'm glad as well.
I actually had a talk with our building manager the other day. He's basically noticed the insane amount of stuff piling up, the walls of incoming/outgoing packages and other things, and I was telling him how we're finally pretty much done with it. He's of course very nice about everything and wouldn't force us to do anything, he just seemed relieved as he's trying to lease the unit down the hall from us and it doesn't look very pretty right now.
I ordered a pizza the other month and the delivery driver was frantically calling me, and said "hey man, I think you guys got robbed, there's computer parts and boxes everywhere, I didn't want you to think I did it." The poor guy thought we were some kind of computer parts store and someone had ransacked our inventory.
@ehab said: @VirMach how to ask for a refund or credits for a pending service?
Just create a ticket in the billing department and mention "refund" in the title. As for credits, it should automatically be adjusted but we do tend to miss that from time to time so if yours activated late and due date wasn't adjusted, again, a ticket explaining it and you'll have it extended or credited.
yeah doesnt work, i think it maybe wont if the current vps is offline.
Is there any different when using migrate button with $3 fee ??
Because i want to try that
nope, i already have one paid in queue since some time ago.
So Virmach payment for move or a ticket are like travel journeys.
Pay up front, the wait for the travel date, which is undefined.
Once this is understood, a lot of anxiety may go away.
I've messaged our developer to see if it's possible to work in an automatic refund if failed system, or other solution. It's not our intention to just hold people's money and have them wonder if it will occur or not and it definitely also isn't something we expected to have to manually process to this level, whether it be for the refunds for the failure or re-processing of a failed migration. Perhaps if we can resolve the payment aspect of it, then we can just close the request and say it failed instead of leaving it in limbo.
@Fritz said:
No migrate button for Japan location anymore.
@Fritz said:
No migrate button for Japan location anymore.
lucky you
Everyone want to move from japan instead because it has many disaster (on vps node) there
This isn't really true but I wish it was.
I believe you mentioned you're on one of the nodes that's offline there, and you also asked about the migration without data, and now you're mentioning everyone wants to move from Japan. Where did you want to move to? I'll move your VPS for you and if anyone else wants to move from Japan to another location let me know here and I'll process it free of charge until we add a system for free migrations from Japan to other locations.
Japan is highly desired and also high in cost for us, so it makes sense that we'd process as many migrations as we can away from it if truly desired.
Just give me your ticket ID here (otherwise it may be closed without response.) Title it something like "Free Migration - No Data - Move Away from TYO"
@cybertech said:
well i hope new kioxias are going into TYOC040
They might. I've been spending some time trying to get the disk issue under control but with everything else going on it's unfortunately delayed. If it takes much longer we might just move forward with a replacement.
@ehab said:
i do not consider buying or renewing anything from them until ship is back sailing as it should.
I'm cancelling vps7 1GB $8.87 deal.
It's still working at the moment but I fear it may go down at any moment.
vps1 1920MB $8.88 deal is too good to be canceled, so I still plan to renew it.
Maybe I'd take a chance and move it away from San Jose where a button press takes more than a week.
We're definitely going to have to have a talk and try to get that location sorted. I'm already considering moving all Flexential locations to other datacenters. We've spoken with others regarding the Dallas location, but Dallas has been improved so far (but probably still bad network, I spoke about that as well.) No-go with QN as it doesn't seem like they have a whole lot of or any staff there. It'll have to be Hivelocity/Carrier1 but any serious talks with them stalled for now as we had a bunch of other issues with them as well.
@yoursunny said: I tried the Ryzen Migrate button to New York, Miami, and Tampa.
None of these options worked.
Miami should definitely work. Can you private message me your account/service details as I'd like to give it a try and see what errors it's throwing.
@yoursunny said:
I tried the Ryzen Migrate button to New York, Miami, and Tampa.
None of these options worked.
I can only hope SJCZ006 doesn't go down, because I don't want to end up in QuadraNet Los Angeles.
If it makes you feel better, there's also a chance of ending up in Hivelocity Los Angeles, which has an amazing network. Truly a mystery lucky dip!
We have at least four more servers going here with room for more (we're just short IPv4.) We weren't planning on doing this location so all IPv4 is already allocated elsewhere, I'll see what I can do to ramp it up.
Anyway, the real reason I came here: NYCB004S is finally back up. Very sorry for all these long outages. This one in particular was challenging to diagnose but it turns out a faulty BBU CacheVault (capacitor instead of battery?) can cause all the symptoms we experienced. We still have a high load issue here which I suspect could be either due to abuse or perhaps other issues we haven't found yet. I'm still working on finalizing it and making sure everything else is healthy.
(edit) Oh and fun fact, a CacheVault/BBU analog for one of these controllers costs $250. I wonder what's the profit margin on that. Most expensive day 1 DLC ever?
Please let me know if anyone here sees any issues with their data. @dedicados tagging you since you said you're on here.
@Virmach if the cpus are overheating, do you not notice that from software temperature monitoring using the sensors in the mobos? This sounds like the boards weren't properly put together with regard to thermal paste etc. They really need to be tested before they go to the dc. Maybe try underclocking. Nobody should be hogging enough cpu to care about losing a little performance on a low end vps like this.
@willie said: @Virmach if the cpus are overheating, do you not notice that from software temperature monitoring using the sensors in the mobos? This sounds like the boards weren't properly put together with regard to thermal paste etc. They really need to be tested before they go to the dc. Maybe try underclocking. Nobody should be hogging enough cpu to care about losing a little performance on a low end vps like this.
They're not overheating, the fans and temperatures are fine. I just think it spontaneously loses stability when it reaches higher usage levels since it's not properly in place. It's not a big issue at other datacenters, we just have them reseat it, but it's an issue at Flexential locations.
I guess a better way to say it is that it seems the likelihood of this problem occurring is amplified proportionately to the CPU usage levels. None of this is scientific, it's just what I've noticed happening that fits these exact symptoms.
I've booked a flight for now and as long as I can get facility access we should be fine. SJCZ004 and SJCZ008 are still online, pending emergency maintenance, if I can get the facility access confirmed, and SJCZ005 (the one that went offline after we got the other two up) seems to be having another problem entirely. That's the reason I decided I need to fly in as I'll have to do some troubleshooting for that one and with the back and forth using DC hands it'll probably take way too long.
This sounds like the boards weren't properly put together with regard to thermal paste etc.
Oh and another note, this actually happens when the thermal paste is applied too well & coincidentally when the thermal paste has properties that make it perform better. The thermal paste is overperforming at its job of filling the gap in between the CPU and heatsink to the point where it exceeds the performance of the latch keeping the CPU on the motherboard.
To reduce the frequency of this problem popping up I actually had to downgrade/change the paste at some point early on (to one that had lower performance in terms of thermals by 1-2C but less likely to grip.)
We were originally using Arctic MX5 but it would cause the problem to occur at a high rate.
"The surfaces of processor chips and cooler floors are covered with microscopic dents; ARCTIC‘s MX-5 thermal paste is composed of carbon microparticles which fill these cavities."
This higher performance, filling in the cavities better, caused it to stick insanely well to the heatsink and the CPU latch and it'd basically be stuck to it so well that minor movements would cause the heatsink plus the CPU to get pulled up a tiny amount. When taking it off, it'd stay stuck to the heatsink pretty much every single time with this specific paste. We switched to another where it wouldn't do that, but it still happened from time to time depending on how rough the specific shipment ended up being.
And there's plenty of negative reviews they get as a result of it being too good:
MX-5 bonds like glue
Some who are super angry because they couldn't get it off properly and damaged their CPU from handling it incorrectly:
DO NOT BUY ARCTIC PRODUCTS
GLUE THERMAL PASTE
If you want your computer destroyed mainly mobo/cpu etc then this is the thermal paste for you.
being I have nothing to lose I will take this to civil court as I have documented everything.
@VirMach said:
We were originally using Arctic MX5 but it would cause the problem to occur at a high rate.
"The surfaces of processor chips and cooler floors are covered with microscopic dents; ARCTIC‘s MX-5 thermal paste is composed of carbon microparticles which fill these cavities."
This higher performance, filling in the cavities better, caused it to stick insanely well to the heatsink and the CPU latch and it'd basically be stuck to it so well that minor movements would cause the heatsink plus the CPU to get pulled up a tiny amount. When taking it off, it'd stay stuck to the heatsink pretty much every single time with this specific paste. We switched to another where it wouldn't do that, but it still happened from time to time depending on how rough the specific shipment ended up being.
And there's plenty of negative reviews they get as a result of it being too good:
MX-5 bonds like glue
Some who are super angry because they couldn't get it off properly and damaged their CPU from handling it incorrectly:
DO NOT BUY ARCTIC PRODUCTS
>
> GLUE THERMAL PASTE
>
> If you want your computer destroyed mainly mobo/cpu etc then this is the thermal paste for you.
>
> being I have nothing to lose I will take this to civil court as I have documented everything.
noctua is good , though unsure in server application.
@VirMach said: 'm already considering moving all Flexential locations to other datacenters.
My VM on DENZ001 has been one of the most stable I have with VirMach. It also seems that I have very few neighbors.
Hopefully you will get Dallas squared away before I have to move out of Denver.
@VirMach said: 'm already considering moving all Flexential locations to other datacenters.
My VM on DENZ001 has been one of the most stable for me. It also seems that I have very few neighbors.
Hopefully you will get Dallas squared away before I have to move out of Denver.
Denver is doing well because no one's using it, lol. We should get more unwanted locations and sell it under our "certified stable" line of services. Well, that is until something goes wrong and it takes longer to fix it due to economies of scale.
@cybertech said: noctua is good , though unsure in server application.
Yeah, that's what was used. It's rated for 5 years but Noctua tends to undersell their products. We also used TG and MX4, as well as some with the pre-applied paste when I was short on time. I tried to keep most of the latter in Los Angeles so I could re-apply them quickly as necessary in case. The pre-applied thermal paste is "Shin-Etsu 7762" which is on AMD's list of recommended thermal pastes and it's been around for several decades so I figured it wouldn't be a disaster.
Another fun fact, they also make grease for squeaky car windows and it's the only thermal paste I know of which you can purchase by the kilos.
@VirMach said: This isn't really true but I wish it was.
I believe you mentioned you're on one of the nodes that's offline there, and you also asked about the migration without data, and now you're mentioning everyone wants to move from Japan. Where did you want to move to? I'll move your VPS for you and if anyone else wants to move from Japan to another location let me know here and I'll process it free of charge until we add a system for free migrations from Japan to other locations.
Japan is highly desired and also high in cost for us, so it makes sense that we'd process as many migrations as we can away from it if truly desired.
Just give me your ticket ID here (otherwise it may be closed without response.) Title it something like "Free Migration - No Data - Move Away from TYO"
865148
Just move it to Frankfurt and pls give me to the most very very stable node, just it thanks
For now on location doesn't matter to me and don't care anymore , just want to server with as minimal hiccup and downtime possible
Everything except SJCZ005 and ATLZ007 are online now, at least for the time being. I'm testing stability and will have a plan for all of them in the afternoon (Sunday) and try to send out emails for at least the first few if we decide to do migrations or scheduled hardware replacements. ATLZ007 has regressed, I can't get it back up. The OS drive is missing now, next step is to either recover that onto another disk or go into rescue and copy everyone off. SJCZ005 is not responding.
But here's a general run-down of the issues faced:
Tokyo had disks disappear and finally re-appear after several reboots and BIOS configuration changes. The disks are healthy and we still have to investigate what happened but it's possible we'll do migrations for those on the disks and then replace them.
Chicago Hivelocity initially had several days, and one of them was related to the switch. The switch became unstable, and we were able to get it back up for the time being. The switch is being switched sometime mid-week.
Tampa is unknown but they're back for now after several reboots and BIOS configuration changes.
San Jose was discussed above. I'm going to attempt to fly in on Monday (changed from Sunday as I didn't hear back from the facility and my flight would leave in a couple hours) and resolve what I can. Once I get confirmation, emails go out.
NYC storage had CacheVault failure as mentioned above. After finally figuring this out after several kernel panics, etc, we overnighted it and it's stable for now. We still need to look into it and see if there's other controller issues.
Los Angeles is a combination of potential power issue and overloading due to I/O errors. I'm going to try to look at the I/O error one with priority to ensure we minimize risk of data loss and for the other schedule a PSU swap if it remains semi-stable.
@VirMach said: We've spoken with others regarding the Dallas location, but Dallas has been improved so far (but probably still bad network, I spoke about that as well.) No-go with QN as it doesn't seem like they have a whole lot of or any staff there. It'll have to be Hivelocity/Carrier1 but any serious talks with them stalled for now as we had a bunch of other issues with them as well.
Yes, network does suck. Why does it have to be Carrier-1? You could go to DallasColo (Equinix/Infomart), or Stack DCs have lower-end options in Dallas, or ...
@VirMach said: 'm already considering moving all Flexential locations to other datacenters.
My VM on DENZ001 has been one of the most stable for me. It also seems that I have very few neighbors.
Hopefully you will get Dallas squared away before I have to move out of Denver.
Denver is doing well because no one's using it, lol. We should get more unwanted locations and sell it under our "certified stable" line of services. Well, that is until something goes wrong and it takes longer to fix it due to economies of scale.
So what you're saying is, I should consider Denver when I need some additional capacity somewhere.
And, as for the software module, is it an open source tool where a patch can be hacked together and applied for a temp fix or is it something that cannot be modified by anyone except the developer?
Anyone else on CHIKVM4? It's been down since the 3rd of August. Can't find any info here or on LET.
All I found are people talking about "VirMach knife chicken CHIKVM4" and Virmach's chicken has become fragrant.
So, @VirMach, is my CHIKVM4 vps now a knife chicken or it became a fragrant?
Gateway is responding to ping, VNCHost is not responding ping, same as my VPS do not.
Hetrixtool script can't POST any data to theirs (Cloudflare?) servers.
noVNC is slooooooooooooooooooooow to load and ends with Failed to connect to server (code: 1006)
WHMCS of course ends with Operation Timed Out After 90001 Milliseconds With 0 Bytes Received
Amsterdaaaaaaaaaaaaaaaaaaaaaam has died?
What is better - mtr-ing VPS IP does not even reach the 'gateway IP' that it uses in theory
Hmm, need to update that timezone! It's 02:15 here. zzzzz
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural. It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
Hello so far I had not commented anything negative to avoid drama but they did not answer the tickets, a VPS service that I have with you is almost 3 weeks off. I also received an email that is attached in the image, I hope they answer the ticket # 588999, thank you very much.
@kheng86 said:
Any reason why FFME006 keeps going down almost everyday? Today it was down for almost 16 hours until it recovered an hour ago.
Show me the network monitor on your end. We've been getting a lot of vague reports like this so it's possible something's wrong but I've never gotten enough information to confirm anything past the control panel connection being choppy. Server itself has an uptime of 53 days on our end.
@VirMach said: We've spoken with others regarding the Dallas location, but Dallas has been improved so far (but probably still bad network, I spoke about that as well.) No-go with QN as it doesn't seem like they have a whole lot of or any staff there. It'll have to be Hivelocity/Carrier1 but any serious talks with them stalled for now as we had a bunch of other issues with them as well.
Yes, network does suck. Why does it have to be Carrier-1? You could go to DallasColo (Equinix/Infomart), or Stack DCs have lower-end options in Dallas, or ...
We're already in Infomart. I don't know enough about DallasColo. Informart would be good if we were in the position to just do our own network blend but we're not right now. Carrier-1/Incero/Hivelocity is a little bit more tried and tested right now and I've researched them since several years ago so I know they're essentially a good fit unless you have any nightmare stories to share.
@/kheng86 said:
Any reason why FFME006 keeps going down almost everyday? Today it was down for almost 16 hours until it recovered an hour ago.
same as LAXA014, except it'll back online after few seconds offline, but it's very bothering, because it keeps rebooting and restarting my app.
can I create ticket with: "Free Migration - No Data - Move Away from LAXA014" @VirMach (LA to LA)?
Don't create that ticket but I understand LAXA014 has been neglected. We did what we could at the time and then it's just been in a weird state since (still.) We need to probably migrate people off and credit everyone as it's been essentially unusable for a month so I understand that. Just with everything else going on, it unfortunately got buried.
I have servers built for LAX1/2 but haven't been able to take them down for several weeks now, my fault.
@VirMach said: Everything except SJCZ005 and ATLZ007 are online now,
I have two SJC VPS on separate nodes and both are unreachable from client area, so I think more than one SJC node is down.
Yeah another one went back down. I've updated the network status page relatively quickly today on that. We're shifting back to trying to use that instead of threads.
@VirMach said: 'm already considering moving all Flexential locations to other datacenters.
My VM on DENZ001 has been one of the most stable for me. It also seems that I have very few neighbors.
Hopefully you will get Dallas squared away before I have to move out of Denver.
Denver is doing well because no one's using it, lol. We should get more unwanted locations and sell it under our "certified stable" line of services. Well, that is until something goes wrong and it takes longer to fix it due to economies of scale.
So what you're saying is, I should consider Denver when I need some additional capacity somewhere.
And, as for the software module, is it an open source tool where a patch can be hacked together and applied for a temp fix or is it something that cannot be modified by anyone except the developer?
Not open source, third party IonCubed. It could technically be purchased open source but I don't think that's our decision to make as I think they need to implement the coding on their end. Our version of the module is just the endpoint. It's possible they have the open source version, but last I heard they're waiting on the main developers to get back to them on something.
And yeah, Denver's a good location to let it coast smoothly until it breaks one day (maybe several years from now, who knows) and then once we're in that situation it'll definitely take much longer to fix because it's Flexential.
@DanSummer said:
Anyone else on CHIKVM4? It's been down since the 3rd of August. Can't find any info here or on LET.
All I found are people talking about "VirMach knife chicken CHIKVM4" and Virmach's chicken has become fragrant.
So, @VirMach, is my CHIKVM4 vps now a knife chicken or it became a fragrant?
You shouldn't be on CHIKVM4. That's completely broken migration. There's like around 12 nodes I'd say that have 1-2 people on them in this state right now. You'd need a priority ticket but we're also aware and I've already assigned someone to fix them.
I'm just glad this was a network anomaly. I immediately noticed AMSD027 and was not ready for another node to have hardware problems.
@cybertech said:
damn was banking on migrating to AMS.
I haven't been able to look into it with everything else going on but I'm by default assuming a big denial of service that took a little bit to get auto nullrouted.
@kidoh said:
Hello so far I had not commented anything negative to avoid drama but they did not answer the tickets, a VPS service that I have with you is almost 3 weeks off. I also received an email that is attached in the image, I hope they answer the ticket # 588999, thank you very much.
We're OK with negative feedback here and understand, as long as it's somewhat constructive.
It's just been impossible to get to these tickets. If you have some solution let me know but we have something like 1,000-2,000 of these tickets that were made every day we migrated people, every day there was a previous outage, and so on. So we can't differentiate between what's already resolved, what was already communicated on a network issue, what was migration related. When we moved tens of thousands of people, this naturally happens and we weren't able to clear them out.
We are independently tracking and working on outages we notice. I'll try to take a quick look at your ticket since it's confirmed as not being one of the above (I assume.) I can't do it right now though, I'll try to remember in a few hours.
(edit) Nevermind not sure how I missed the ATLZ007 part. So this would, assuming it's ATLZ007, be part of the tickets clogging up the system right now and already being worked on.
@VirMach said: We've spoken with others regarding the Dallas location, but Dallas has been improved so far (but probably still bad network, I spoke about that as well.) No-go with QN as it doesn't seem like they have a whole lot of or any staff there. It'll have to be Hivelocity/Carrier1 but any serious talks with them stalled for now as we had a bunch of other issues with them as well.
Yes, network does suck. Why does it have to be Carrier-1? You could go to DallasColo (Equinix/Infomart), or Stack DCs have lower-end options in Dallas, or ...
We're already in Infomart. I don't know enough about DallasColo. Informart would be good if we were in the position to just do our own network blend but we're not right now. Carrier-1/Incero/Hivelocity is a little bit more tried and tested right now and I've researched them since several years ago so I know they're essentially a good fit unless you have any nightmare stories to share.
Carrier-1 is fine, there's no particular reason for you to avoid them. It was more questioning why limit your options.
The problem is not so much Infomart as whoever's gear is upstream. There's been 4 network issues resulting in Hetrix/AWS detecting Virmach DFW servers as down just today. At the same time, it seems to take out my VPS from Dedipath, Nexril, etc., so I don't believe it is you.
Infomart is pretty big and I'm suspecting you don't necessarily need to dump the whole facility to solve the problem. For example, Clouvider is in Equinix DA11 at Infomart and I don't see them falling over 4x per day.
@VirMach said:
You shouldn't be on CHIKVM4. That's completely broken migration. There's like around 12 nodes I'd say that have 1-2 people on them in this state right now. You'd need a priority ticket but we're also aware and I've already assigned someone to fix them.
Can confirm as someone also on that older host with one vps that I've had a priority ticket since the 15th when you mentioned doing it (I was trying to not add to tickets before that) on the issue. It's still not been touched, so may need to poke that person if they think they are done
@tetech said:
Infomart is pretty big and I'm suspecting you don't necessarily need to dump the whole facility to solve the problem. For example, Clouvider is in Equinix DA11 at Infomart and I don't see them falling over 4x per day.
Yeah, Infomart is a massive 1.5 million square foot building full of datacenters & interconnects basically. It's also a neat looking place, being modeled after the Crystal Palace from one of the Great Exhibitions of the 1800s in London.
The issue there is more of knowing the good options, all my info is horribly out of date as I last worked in the building in 2007 and it has changed owners a few times. I believe Equinix still owns it currently so they probably have a number of different suites setup with different blends / tiers of connections.
Edit: Looking at Equinix's site, DA11 is actually just physically outside the main Infomart building but it's prob on the same hospital+ grade power grid and stuff.
Hello, @VirMach. I haven't seen it mentioned anywhere, but TYOC025 has had problems since late July as well. The server has always seemed to be up, but there has never been any network connection. When trying to click "Fix Internet/Reconfigure Network", it just returns with "Operation Timed Out After 90001 Milliseconds With 0 Bytes Received" and never resolves the issue.
Since I haven't seen TYOC025 mentioned as being an issue elsewhere, please check ticket if you need specific details: #265313
@VirMach said:
You shouldn't be on CHIKVM4. That's completely broken migration. There's like around 12 nodes I'd say that have 1-2 people on them in this state right now. You'd need a priority ticket but we're also aware and I've already assigned someone to fix them.
Can confirm as someone also on that older host with one vps that I've had a priority ticket since the 15th when you mentioned doing it (I was trying to not add to tickets before that) on the issue. It's still not been touched, so may need to poke that person if they think they are done
@VirMach said: We've spoken with others regarding the Dallas location, but Dallas has been improved so far (but probably still bad network, I spoke about that as well.) No-go with QN as it doesn't seem like they have a whole lot of or any staff there. It'll have to be Hivelocity/Carrier1 but any serious talks with them stalled for now as we had a bunch of other issues with them as well.
Yes, network does suck. Why does it have to be Carrier-1? You could go to DallasColo (Equinix/Infomart), or Stack DCs have lower-end options in Dallas, or ...
We're already in Infomart. I don't know enough about DallasColo. Informart would be good if we were in the position to just do our own network blend but we're not right now. Carrier-1/Incero/Hivelocity is a little bit more tried and tested right now and I've researched them since several years ago so I know they're essentially a good fit unless you have any nightmare stories to share.
Carrier-1 is fine, there's no particular reason for you to avoid them. It was more questioning why limit your options.
The problem is not so much Infomart as whoever's gear is upstream. There's been 4 network issues resulting in Hetrix/AWS detecting Virmach DFW servers as down just today. At the same time, it seems to take out my VPS from Dedipath, Nexril, etc., so I don't believe it is you.
Infomart is pretty big and I'm suspecting you don't necessarily need to dump the whole facility to solve the problem. For example, Clouvider is in Equinix DA11 at Infomart and I don't see them falling over 4x per day.
Yeah we're not limiting our options. We actually took both Infomart through Dedipath and Carrier-1 through Psychz but we know how that one went. I just meant specifically what I assume to be Carrier1 --> Incero --> Hivelocity to be a specific partner that I know of which could make it happen to a better level and didn't know anyone else in Infomart that could provide the more direct level of staff/access we require.
Open to any suggestions that ends up being in Infomart but it can't be something like Infomart --> Flexential --> Dedipath where the people in the middle (Flexential) are refusing or unable to complete our requests.
@VirMach said: San Jose was discussed above. I'm going to attempt to fly in on Monday (changed from Sunday as I didn't hear back from the facility and my flight would leave in a couple hours) and resolve what I can. Once I get confirmation, emails go out.
I just woke up after a nap for my flight and found that it's been cancelled. No use calling them to figure out what happened. I'm going to try to get at least portions of the maintenance done with emergency hands instead since we specifically sent out emails for the 8AM to 12PM timeslot, but it'll most likely go poorly.
A little bit disoriented right now but I'm grabbing some coffee and will hash out a plan.


Comments
This may actually be helpful if it can be coordinated. The issue we've noticed that manifests itself into the problem we're observing has essentially for the most part been the CPU getting "loose" due to the way the pins work on the AM4 platform. Basically, the thermal paste creates a good adhesion -- too good, and it ends up creating some kind of "suction" where the heatsink is prone to pulling off the CPU since the motherboard has a weak latch. During shipping, the pins get pulled up and I assume they have a loose connection, which results in the server going "offline" in the same manner it would if the CPU was missing or has a bent pin. The motherboard is still getting power so the BMC chip continues functioning, but we're unable to boot it back up.
This also tends to also occur if we have a bad DIMM, but we already sorted out memory errors with RAM swaps in San Jose. It's still a possibility. It could also technically be a cable but that's less likely to just boot back up.
One co-morbidity seems to be high CPU usage. Past a threshold, I assume in some way related to the wattage or boosting, is when it seems to occur. These servers in San Jose still don't have the switch configuration changes, meaning naturally higher CPU usage just to keep the NIC going, not necessarily any abuse or overselling.
I'm going to try pushing a switch configuration change (VLANs) with our provider. One main problem we've been having is that they were set up very messy with this specific provider which caused a lot of grief in the past, as port numbers were mislabeled, so it extended the whole process and caused a lot of outages which we'd want to avoid this time around. That would reduce CPU usage, reduce the chances of it occurring again for now, and facilitate migrations to Los Angeles.
The problem with doing a CPU swap that we've noticed is that DC hands, even if they're willing, tend to have a hard time removing the CPU as it gets stuck to the heatsink, and it's very easy to screw it up and bend the CPU pins. We've had this happen before and of the DC hands aren't quick to admit it so it ends up with the server going from slightly unusable to fully broken.
Software.
We'll have everything wrapped up by then and I probably do not want to do a BF sale but we may have to end up doing it. Here, I'll promise one thing and make sure to remind me of it a week before BF: if the consensus is that we haven't gone everything stable & done, let me know and we'll definitely cancel the BF sale.
Between the broken website, a year plus of not having our main non-sale product (licensed Windows VPS), the migrations/transition to Ryzen, the dedicated server fiasco, and many other factors, we haven't exactly been meeting revenue targets. While it's nowhere near a "critical" stage and we're doing fine and will continue doing fine, we do technically need to recoup the costs associated with purchasing a ton of brand new hardware and at the very least it would help with our continued expansion if we had another big boost of revenue to purchase more Ryzen sooner.
I'm still definitely considering other options just to avoid doing a BF sale. As much as I love doing a crazy sale, I would personally love to instead take some time off this year.
Thank you, I'm glad as well.
I actually had a talk with our building manager the other day. He's basically noticed the insane amount of stuff piling up, the walls of incoming/outgoing packages and other things, and I was telling him how we're finally pretty much done with it. He's of course very nice about everything and wouldn't force us to do anything, he just seemed relieved as he's trying to lease the unit down the hall from us and it doesn't look very pretty right now.
I ordered a pizza the other month and the delivery driver was frantically calling me, and said "hey man, I think you guys got robbed, there's computer parts and boxes everywhere, I didn't want you to think I did it." The poor guy thought we were some kind of computer parts store and someone had ransacked our inventory.
Just create a ticket in the billing department and mention "refund" in the title. As for credits, it should automatically be adjusted but we do tend to miss that from time to time so if yours activated late and due date wasn't adjusted, again, a ticket explaining it and you'll have it extended or credited.
I've messaged our developer to see if it's possible to work in an automatic refund if failed system, or other solution. It's not our intention to just hold people's money and have them wonder if it will occur or not and it definitely also isn't something we expected to have to manually process to this level, whether it be for the refunds for the failure or re-processing of a failed migration. Perhaps if we can resolve the payment aspect of it, then we can just close the request and say it failed instead of leaving it in limbo.
That's good, it means it's working.
This isn't really true but I wish it was.
I believe you mentioned you're on one of the nodes that's offline there, and you also asked about the migration without data, and now you're mentioning everyone wants to move from Japan. Where did you want to move to? I'll move your VPS for you and if anyone else wants to move from Japan to another location let me know here and I'll process it free of charge until we add a system for free migrations from Japan to other locations.
Japan is highly desired and also high in cost for us, so it makes sense that we'd process as many migrations as we can away from it if truly desired.
Just give me your ticket ID here (otherwise it may be closed without response.) Title it something like "Free Migration - No Data - Move Away from TYO"
They might. I've been spending some time trying to get the disk issue under control but with everything else going on it's unfortunately delayed. If it takes much longer we might just move forward with a replacement.
We're definitely going to have to have a talk and try to get that location sorted. I'm already considering moving all Flexential locations to other datacenters. We've spoken with others regarding the Dallas location, but Dallas has been improved so far (but probably still bad network, I spoke about that as well.) No-go with QN as it doesn't seem like they have a whole lot of or any staff there. It'll have to be Hivelocity/Carrier1 but any serious talks with them stalled for now as we had a bunch of other issues with them as well.
Miami should definitely work. Can you private message me your account/service details as I'd like to give it a try and see what errors it's throwing.
We have at least four more servers going here with room for more (we're just short IPv4.) We weren't planning on doing this location so all IPv4 is already allocated elsewhere, I'll see what I can do to ramp it up.
Anyway, the real reason I came here: NYCB004S is finally back up. Very sorry for all these long outages. This one in particular was challenging to diagnose but it turns out a faulty BBU CacheVault (capacitor instead of battery?) can cause all the symptoms we experienced. We still have a high load issue here which I suspect could be either due to abuse or perhaps other issues we haven't found yet. I'm still working on finalizing it and making sure everything else is healthy.
(edit) Oh and fun fact, a CacheVault/BBU analog for one of these controllers costs $250. I wonder what's the profit margin on that. Most expensive day 1 DLC ever?
Please let me know if anyone here sees any issues with their data. @dedicados tagging you since you said you're on here.
@Virmach if the cpus are overheating, do you not notice that from software temperature monitoring using the sensors in the mobos? This sounds like the boards weren't properly put together with regard to thermal paste etc. They really need to be tested before they go to the dc. Maybe try underclocking. Nobody should be hogging enough cpu to care about losing a little performance on a low end vps like this.
They're not overheating, the fans and temperatures are fine. I just think it spontaneously loses stability when it reaches higher usage levels since it's not properly in place. It's not a big issue at other datacenters, we just have them reseat it, but it's an issue at Flexential locations.
I guess a better way to say it is that it seems the likelihood of this problem occurring is amplified proportionately to the CPU usage levels. None of this is scientific, it's just what I've noticed happening that fits these exact symptoms.
I've booked a flight for now and as long as I can get facility access we should be fine. SJCZ004 and SJCZ008 are still online, pending emergency maintenance, if I can get the facility access confirmed, and SJCZ005 (the one that went offline after we got the other two up) seems to be having another problem entirely. That's the reason I decided I need to fly in as I'll have to do some troubleshooting for that one and with the back and forth using DC hands it'll probably take way too long.
Oh and another note, this actually happens when the thermal paste is applied too well & coincidentally when the thermal paste has properties that make it perform better. The thermal paste is overperforming at its job of filling the gap in between the CPU and heatsink to the point where it exceeds the performance of the latch keeping the CPU on the motherboard.
To reduce the frequency of this problem popping up I actually had to downgrade/change the paste at some point early on (to one that had lower performance in terms of thermals by 1-2C but less likely to grip.)
We were originally using Arctic MX5 but it would cause the problem to occur at a high rate.
"The surfaces of processor chips and cooler floors are covered with microscopic dents; ARCTIC‘s MX-5 thermal paste is composed of carbon microparticles which fill these cavities."
This higher performance, filling in the cavities better, caused it to stick insanely well to the heatsink and the CPU latch and it'd basically be stuck to it so well that minor movements would cause the heatsink plus the CPU to get pulled up a tiny amount. When taking it off, it'd stay stuck to the heatsink pretty much every single time with this specific paste. We switched to another where it wouldn't do that, but it still happened from time to time depending on how rough the specific shipment ended up being.
And there's plenty of negative reviews they get as a result of it being too good:
Some who are super angry because they couldn't get it off properly and damaged their CPU from handling it incorrectly:
noctua is good , though unsure in server application.
I bench YABS 24/7/365 unless it's a leap year.
My VM on DENZ001 has been one of the most stable I have with VirMach. It also seems that I have very few neighbors.
Hopefully you will get Dallas squared away before I have to move out of Denver.
Denver is doing well because no one's using it, lol. We should get more unwanted locations and sell it under our "certified stable" line of services. Well, that is until something goes wrong and it takes longer to fix it due to economies of scale.
Yeah, that's what was used. It's rated for 5 years but Noctua tends to undersell their products. We also used TG and MX4, as well as some with the pre-applied paste when I was short on time. I tried to keep most of the latter in Los Angeles so I could re-apply them quickly as necessary in case. The pre-applied thermal paste is "Shin-Etsu 7762" which is on AMD's list of recommended thermal pastes and it's been around for several decades so I figured it wouldn't be a disaster.
Another fun fact, they also make grease for squeaky car windows and it's the only thermal paste I know of which you can purchase by the kilos.
I believe you mentioned you're on one of the nodes that's offline there, and you also asked about the migration without data, and now you're mentioning everyone wants to move from Japan. Where did you want to move to? I'll move your VPS for you and if anyone else wants to move from Japan to another location let me know here and I'll process it free of charge until we add a system for free migrations from Japan to other locations.
Japan is highly desired and also high in cost for us, so it makes sense that we'd process as many migrations as we can away from it if truly desired.
Just give me your ticket ID here (otherwise it may be closed without response.) Title it something like "Free Migration - No Data - Move Away from TYO"
865148
Just move it to Frankfurt and pls give me to the most very very stable node, just it thanks
For now on location doesn't matter to me and don't care anymore , just want to server with as minimal hiccup and downtime possible
never mind.
Pretty successful day.
Everything except SJCZ005 and ATLZ007 are online now, at least for the time being. I'm testing stability and will have a plan for all of them in the afternoon (Sunday) and try to send out emails for at least the first few if we decide to do migrations or scheduled hardware replacements. ATLZ007 has regressed, I can't get it back up. The OS drive is missing now, next step is to either recover that onto another disk or go into rescue and copy everyone off. SJCZ005 is not responding.
But here's a general run-down of the issues faced:
Any others I missed, feel free to ask about it.
SJCZ004 is still offline, paid for migration but failed to complete.
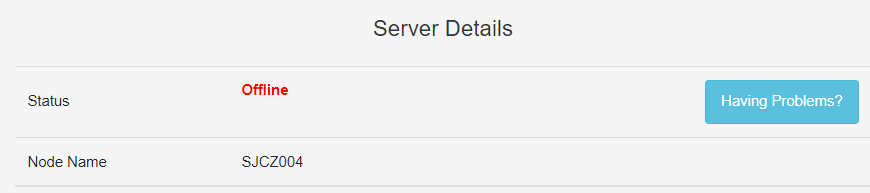
Ticket #461588
@VirMach
Any reason why FFME006 keeps going down almost everyday? Today it was down for almost 16 hours until it recovered an hour ago.
Yes, network does suck. Why does it have to be Carrier-1? You could go to DallasColo (Equinix/Infomart), or Stack DCs have lower-end options in Dallas, or ...
same as LAXA014, except it'll back online after few seconds offline, but it's very bothering, because it keeps rebooting and restarting my app.
can I create ticket with: "Free Migration - No Data - Move Away from LAXA014" @VirMach (LA to LA)?
I have two SJC VPS on separate nodes and both are unreachable from client area, so I think more than one SJC node is down.
So what you're saying is, I should consider Denver when I need some additional capacity somewhere.
And, as for the software module, is it an open source tool where a patch can be hacked together and applied for a temp fix or is it something that cannot be modified by anyone except the developer?
Anyone else on CHIKVM4? It's been down since the 3rd of August. Can't find any info here or on LET.
All I found are people talking about "VirMach knife chicken CHIKVM4" and Virmach's chicken has become fragrant.
So, @VirMach, is my CHIKVM4 vps now a knife chicken or it became a fragrant?
Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png
Okey, that "UP" was missleading, it died again.

Gateway is responding to ping, VNCHost is not responding ping, same as my VPS do not.
Hetrixtool script can't POST any data to theirs (Cloudflare?) servers.
noVNC is slooooooooooooooooooooow to load and ends with
Failed to connect to server (code: 1006)WHMCS of course ends with
Operation Timed Out After 90001 Milliseconds With 0 Bytes ReceivedAmsterdaaaaaaaaaaaaaaaaaaaaaam has died?
What is better - mtr-ing VPS IP does not even reach the 'gateway IP' that it uses in theory
mtr-ing gateway works...
Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png
damn was banking on migrating to AMS.
I bench YABS 24/7/365 unless it's a leap year.
AMS had been stable for many weeks. Looks as though it was a network thing..
Hmm, need to update that timezone! It's 02:15 here. zzzzz
In stasis until the shitposting stops/abates.
Than=compare;then=sequence:brought=bring;bought=buy:staffs=pile of sticks:informations/infos=no plural.
It wisnae me! A big boy done it and ran away. || NVMe2G for life! until death (the end is nigh).
aaaaaaaaaaaand it's back online.
All we (I, okey?) had to do is complain in LowEndSpirit ;')
Haven't bought a single service in VirMach Great Ryzen 2022 - 2023 Flash Sale.
https://lowendspirit.com/uploads/editor/gi/ippw0lcmqowk.png
Hello so far I had not commented anything negative to avoid drama but they did not answer the tickets, a VPS service that I have with you is almost 3 weeks off. I also received an email that is attached in the image, I hope they answer the ticket # 588999, thank you very much.")

Show me the network monitor on your end. We've been getting a lot of vague reports like this so it's possible something's wrong but I've never gotten enough information to confirm anything past the control panel connection being choppy. Server itself has an uptime of 53 days on our end.
We're already in Infomart. I don't know enough about DallasColo. Informart would be good if we were in the position to just do our own network blend but we're not right now. Carrier-1/Incero/Hivelocity is a little bit more tried and tested right now and I've researched them since several years ago so I know they're essentially a good fit unless you have any nightmare stories to share.
Don't create that ticket but I understand LAXA014 has been neglected. We did what we could at the time and then it's just been in a weird state since (still.) We need to probably migrate people off and credit everyone as it's been essentially unusable for a month so I understand that. Just with everything else going on, it unfortunately got buried.
I have servers built for LAX1/2 but haven't been able to take them down for several weeks now, my fault.
Yeah another one went back down. I've updated the network status page relatively quickly today on that. We're shifting back to trying to use that instead of threads.
Not open source, third party IonCubed. It could technically be purchased open source but I don't think that's our decision to make as I think they need to implement the coding on their end. Our version of the module is just the endpoint. It's possible they have the open source version, but last I heard they're waiting on the main developers to get back to them on something.
And yeah, Denver's a good location to let it coast smoothly until it breaks one day (maybe several years from now, who knows) and then once we're in that situation it'll definitely take much longer to fix because it's Flexential.
You shouldn't be on CHIKVM4. That's completely broken migration. There's like around 12 nodes I'd say that have 1-2 people on them in this state right now. You'd need a priority ticket but we're also aware and I've already assigned someone to fix them.
I'm just glad this was a network anomaly. I immediately noticed AMSD027 and was not ready for another node to have hardware problems.
I haven't been able to look into it with everything else going on but I'm by default assuming a big denial of service that took a little bit to get auto nullrouted.
We're OK with negative feedback here and understand, as long as it's somewhat constructive.
It's just been impossible to get to these tickets. If you have some solution let me know but we have something like 1,000-2,000 of these tickets that were made every day we migrated people, every day there was a previous outage, and so on. So we can't differentiate between what's already resolved, what was already communicated on a network issue, what was migration related. When we moved tens of thousands of people, this naturally happens and we weren't able to clear them out.
We are independently tracking and working on outages we notice. I'll try to take a quick look at your ticket since it's confirmed as not being one of the above (I assume.) I can't do it right now though, I'll try to remember in a few hours.
(edit) Nevermind not sure how I missed the ATLZ007 part. So this would, assuming it's ATLZ007, be part of the tickets clogging up the system right now and already being worked on.
Carrier-1 is fine, there's no particular reason for you to avoid them. It was more questioning why limit your options.
The problem is not so much Infomart as whoever's gear is upstream. There's been 4 network issues resulting in Hetrix/AWS detecting Virmach DFW servers as down just today. At the same time, it seems to take out my VPS from Dedipath, Nexril, etc., so I don't believe it is you.
Infomart is pretty big and I'm suspecting you don't necessarily need to dump the whole facility to solve the problem. For example, Clouvider is in Equinix DA11 at Infomart and I don't see them falling over 4x per day.
@VirMach Any news about my ticket about migration ?
865148
Or i should make new specific ticket like u said include with word Title "Free Migration - No Data - Move Away from TYO" ???
Can confirm as someone also on that older host with one vps that I've had a priority ticket since the 15th when you mentioned doing it (I was trying to not add to tickets before that) on the issue. It's still not been touched, so may need to poke that person if they think they are done")
Yeah, Infomart is a massive 1.5 million square foot building full of datacenters & interconnects basically. It's also a neat looking place, being modeled after the Crystal Palace from one of the Great Exhibitions of the 1800s in London.
The issue there is more of knowing the good options, all my info is horribly out of date as I last worked in the building in 2007 and it has changed owners a few times. I believe Equinix still owns it currently so they probably have a number of different suites setup with different blends / tiers of connections.
Edit: Looking at Equinix's site, DA11 is actually just physically outside the main Infomart building but it's prob on the same hospital+ grade power grid and stuff.
Hello, @VirMach. I haven't seen it mentioned anywhere, but TYOC025 has had problems since late July as well. The server has always seemed to be up, but there has never been any network connection. When trying to click "Fix Internet/Reconfigure Network", it just returns with "Operation Timed Out After 90001 Milliseconds With 0 Bytes Received" and never resolves the issue.
Since I haven't seen TYOC025 mentioned as being an issue elsewhere, please check ticket if you need specific details: #265313
Looks like I need to do some poking.
Yeah we're not limiting our options. We actually took both Infomart through Dedipath and Carrier-1 through Psychz but we know how that one went. I just meant specifically what I assume to be Carrier1 --> Incero --> Hivelocity to be a specific partner that I know of which could make it happen to a better level and didn't know anyone else in Infomart that could provide the more direct level of staff/access we require.
Open to any suggestions that ends up being in Infomart but it can't be something like Infomart --> Flexential --> Dedipath where the people in the middle (Flexential) are refusing or unable to complete our requests.
I just woke up after a nap for my flight and found that it's been cancelled. No use calling them to figure out what happened. I'm going to try to get at least portions of the maintenance done with emergency hands instead since we specifically sent out emails for the 8AM to 12PM timeslot, but it'll most likely go poorly.
A little bit disoriented right now but I'm grabbing some coffee and will hash out a plan.